
-
18 Introducción
-
18.1 Muestreadores
- Solicitud FTP
- Solicitud HTTP
- Solicitud JDBC
- Solicitud Java
- Solicitud LDAP
- Solicitud extendida de LDAP
- Muestreador de registro de acceso
- Muestreador BeanShell
- Muestreador JSR223
- Muestreador de TCP
- Editor JMS
- Suscriptor JMS
- JMS punto a punto
- Solicitud JUnit
- Muestra de lector de correo
- Acción de control de flujo (era: Acción de prueba)
- Muestreador SMTP
- Muestreador de procesos del sistema operativo
- Secuencia de comandos MongoDB (EN OBSEQUIO)
- Solicitud de perno
-
18.2 Controladores lógicos
- Controlador sencillo
- Controlador de bucle
- Controlador de una sola vez
- Controlador intercalado
- Controlador aleatorio
- Controlador de orden aleatorio
- Controlador de rendimiento
- Controlador de tiempo de ejecución
- Si el controlador
- Mientras que el controlador
- Controlador de interruptores
- Para cada controlador
- Controlador de módulo
- Incluir controlador
- Controlador de transacciones
- Controlador de grabación
- Controlador de secciones críticas
-
18.3 Oyentes
- Ejemplo de configuración para guardar resultados
- Resultados del gráfico
- Resultados de aserción
- Ver árbol de resultados
- Informe agregado
- Ver resultados en la tabla
- Escritor de datos simple
- Gráfico agregado
- Gráfico de tiempo de respuesta
- Visualizador de correo
- Oyente BeanShell
- Informe resumido
- Guardar respuestas en un archivo
- Oyente JSR223
- Generar resultados de resumen
- Visualizador de afirmación de comparación
- Oyente de back-end
-
18.4 Elementos de configuración
- Configuración del conjunto de datos CSV
- Valores predeterminados de solicitud de FTP
- Administrador de caché de DNS
- Administrador de autorización HTTP
- Administrador de caché HTTP
- Administrador de cookies HTTP
- Valores predeterminados de solicitud HTTP
- Administrador de encabezado HTTP
- Valores predeterminados de solicitud de Java
- Configuración de conexión JDBC
- Configuración del almacén de claves
- Elemento de configuración de inicio de sesión
- Valores predeterminados de solicitud LDAP
- Valores predeterminados de solicitud extendida de LDAP
- Configuración del muestreador de TCP
- Variables definidas por el usuario
- Variable aleatoria
- Encimera
- Elemento de configuración simple
- Configuración de origen de MongoDB (OBSOLETO)
- Configuración de conexión de pernos
- 18.5 Aserciones
- 18.6 Temporizadores
- 18.7 Preprocesadores
-
18.8 Postprocesadores
- Extractor de expresiones regulares
- Extractor de selector de CSS (antes: Extractor de CSS/JQuery)
- Extractor XPath2
- Extractor de XPath
- JSON JMESPath Extractor
- Controlador de acción de estado de resultado
- Postprocesador BeanShell
- Postprocesador JSR223
- Postprocesador JDBC
- Extractor JSON
- Extractor de límites
-
18.9 Funciones misceláneas
- Plan de prueba
- Grupo de hilos
- banco de trabajo
- Administrador de SSL
- Grabadora de secuencias de comandos de prueba HTTP(S) (antes: servidor proxy HTTP)
- Servidor espejo HTTP
- Visualización de propiedades
- Muestreador de depuración
- Postprocesador de depuración
- Fragmento de prueba
- configurar grupo de subprocesos
- Grupo de hilos de desmontaje
18 Introducción ¶
18.1 Muestreadores ¶
Los muestreadores realizan el trabajo real de JMeter. Cada muestreador (excepto la Acción de control de flujo ) genera uno o más resultados de muestra. Los resultados de la muestra tienen varios atributos (éxito/fallo, tiempo transcurrido, tamaño de datos, etc.) y se pueden ver en varios oyentes.
Petición FTP ¶
La latencia se establece en el tiempo que lleva iniciar sesión.

Parámetros ¶
Solicitud HTTP ¶
Esta muestra le permite enviar una solicitud HTTP/HTTPS a un servidor web. También le permite controlar si JMeter analiza o no los archivos HTML en busca de imágenes y otros recursos incrustados y envía solicitudes HTTP para recuperarlos. Se recuperan los siguientes tipos de recursos incrustados:
- imágenes
- subprogramas
- hojas de estilo (CSS) y recursos a los que se hace referencia desde esos archivos
- guiones externos
- marcos, iframes
- imágenes de fondo (cuerpo, tabla, TD, TR)
- sonido de fondo
El analizador predeterminado es org.apache.jmeter.protocol.http.parser.LagartoBasedHtmlParser . Esto se puede cambiar utilizando la propiedad " htmlparser.className "; consulte jmeter.properties para obtener más información.
Si va a enviar varias solicitudes al mismo servidor web, considere usar un elemento de configuración de valores predeterminados de solicitud HTTP para que no tenga que ingresar la misma información para cada solicitud HTTP.
O bien, en lugar de agregar solicitudes HTTP manualmente, es posible que desee utilizar la grabadora de secuencias de comandos de prueba HTTP(S) de JMeter para crearlas. Esto puede ahorrarle tiempo si tiene muchas solicitudes HTTP o solicitudes con muchos parámetros.
Hay tres elementos de prueba diferentes que se utilizan para definir los muestreadores:
- Muestreador AJP/1.3
- usa el protocolo Tomcat mod_jk (permite probar Tomcat en modo AJP sin necesidad de Apache httpd) El AJP Sampler no admite la carga de múltiples archivos; sólo se utilizará el primer archivo.
- Solicitud HTTP
- Esto tiene un cuadro desplegable de implementación, que selecciona la implementación del protocolo HTTP que se va a usar:
- Java
- utiliza la implementación HTTP proporcionada por la JVM. Esto tiene algunas limitaciones en comparación con las implementaciones de HttpClient; consulte a continuación.
- Cliente HTTP4
- utiliza Apache HttpComponents HttpClient 4.x.
- Valor en blanco
- no establece la implementación en HTTP Samplers, por lo que se basa en los valores predeterminados de solicitud HTTP si están presentes o en la propiedad jmeter.httpsampler definida en jmeter.properties
- Solicitud HTTP de GraphQL
- Esta es una variación de la GUI de la solicitud HTTP para proporcionar elementos de la IU más convenientes para ver o editar la consulta GraphQL , las variables y el nombre de la operación , mientras los convierte en argumentos HTTP automáticamente bajo el capó usando la misma muestra. Esto oculta o personaliza los siguientes elementos de la interfaz de usuario, ya que son menos convenientes o irrelevantes para GraphQL a través de solicitudes HTTP/HTTPS:
- Método : solo los métodos POST y GET están disponibles conforme a la especificación GraphQL sobre HTTP. El método POST está seleccionado de forma predeterminada.
- Pestañas Parámetros y Cuerpo de la publicación : en su lugar, puede ver o editar el contenido de los parámetros a través de los elementos de la interfaz de usuario Consulta, Variables y Nombre de la operación.
- Pestaña Carga de archivo : irrelevante para las consultas de GraphQL.
- Recursos incrustados de la sección Archivos HTML en la pestaña Avanzado: irrelevante en las respuestas GraphQL JSON.
La implementación de Java HTTP tiene algunas limitaciones:
- No hay control sobre cómo se reutilizan las conexiones. Cuando JMeter libera una conexión, puede o no ser reutilizada por el mismo subproceso.
- La API se adapta mejor al uso de un solo subproceso: varias configuraciones se definen a través de las propiedades del sistema y, por lo tanto, se aplican a todas las conexiones.
- Sin soporte de autenticación Kerberos
- No es compatible con las pruebas de certificados basadas en clientes con Keystore Config.
- Mejor control del mecanismo de reintento
- No es compatible con hosts virtuales.
- Solo admite los siguientes métodos: GET , POST , HEAD , OPTIONS , PUT , DELETE y TRACE
- Mejor control sobre el almacenamiento en caché de DNS con DNS Cache Manager
Si la solicitud requiere autorización de inicio de sesión de servidor o proxy (es decir, cuando un navegador crearía un cuadro de diálogo emergente), también deberá agregar un elemento de configuración del administrador de autorización HTTP . Para los inicios de sesión normales (es decir, cuando el usuario ingresa la información de inicio de sesión en un formulario), deberá averiguar qué hace el botón de envío del formulario y crear una solicitud HTTP con el método apropiado (generalmente POST ) y los parámetros apropiados de la definición del formulario. . Si la página usa HTTP, puede usar JMeter Proxy para capturar la secuencia de inicio de sesión.
Se utiliza un contexto SSL independiente para cada subproceso. Si desea utilizar un solo contexto SSL (no el comportamiento estándar de los navegadores), configure la propiedad JMeter:
https.sessioncontext.shared=trueDe forma predeterminada, desde la versión 5.0, el contexto SSL se conserva durante una iteración de grupo de subprocesos y se restablece para cada iteración de prueba. Si en su plan de prueba el mismo usuario itera varias veces, debe establecerlo en falso.
httpclient.reset_state_on_thread_group_iteration=true
https.predeterminado.protocolo=SSLv3
JMeter también permite habilitar protocolos adicionales, cambiando la propiedad https.socket.protocols .
Si la solicitud utiliza cookies, también necesitará un administrador de cookies HTTP . Puede agregar cualquiera de estos elementos al grupo de subprocesos o a la solicitud HTTP. Si tiene más de una solicitud HTTP que necesita autorizaciones o cookies, agregue los elementos al grupo de subprocesos. De esa forma, todos los controladores de solicitudes HTTP compartirán los mismos elementos del Administrador de autorización y el Administrador de cookies.
Si la solicitud utiliza una técnica llamada "Reescritura de URL" para mantener las sesiones, consulte la sección 6.1 Manejo de sesiones de usuario con reescritura de URL para conocer los pasos de configuración adicionales.




Parámetros ¶
- lo proporciona HTTP Request Defaults
- o se establece una URL completa que incluye esquema, host y puerto ( esquema: // host: puerto ) en el campo Ruta
Se puede usar una aserción de duración para detectar respuestas que tardan demasiado en completarse.
Se pueden predefinir más métodos para HttpClient4 mediante el uso de la propiedad httpsampler.user_defined_methods de JMeter .
"Redireccionamiento solicitado pero followRedirects está deshabilitado"Esto puede ser ignorado.
JMeter colapsará las rutas de la forma ' /../segment ' en las URL de redirección absolutas y relativas. Por ejemplo , http://host/one/../two se colapsará en http://host/two . Si es necesario, este comportamiento se puede suprimir configurando la propiedad JMeter httpsampler.redirect.removeslashdotdot=false
Además, puede especificar si cada parámetro debe codificarse como URL. Si no está seguro de lo que esto significa, probablemente sea mejor seleccionarlo. Si sus valores contienen caracteres como los siguientes, generalmente se requiere codificación:
- Caracteres de control ASCII
- Caracteres no ASCII
- Caracteres reservados: las URL usan algunos caracteres para uso especial al definir su sintaxis. Cuando estos caracteres no se utilizan en su función especial dentro de una URL, deben codificarse, por ejemplo: ' $ ', ' & ', ' + ', ' , ' , ' / ', ' : ', ' ; ', ' = ', ' ? ', ' @ '
- Caracteres no seguros: algunos caracteres presentan la posibilidad de ser malinterpretados dentro de las URL por varias razones. Estos caracteres también deben estar siempre codificados, ejemplo: ' ', ' < ', ' > ', ' # ', ' % ', …
Si se trata de una solicitud POST , PUT o PATCH y hay un solo archivo cuyo atributo 'Nombre del parámetro' (a continuación) se omite, el archivo se envía como el cuerpo completo de la solicitud, es decir, no se agregan envoltorios. Esto permite enviar cuerpos arbitrarios. Esta funcionalidad está presente para las solicitudes POST y también para las solicitudes PUT . Consulte a continuación para obtener más información sobre el manejo de parámetros.
Para distinguir el valor de la dirección de origen, seleccione el tipo de estos:
- Seleccione IP/Nombre de host para usar una dirección IP específica o un nombre de host (local)
- Seleccione Dispositivo para elegir la primera dirección disponible para esa interfaz, que puede ser IPv4 o IPv6
- Seleccione Dispositivo IPv4 para seleccionar la dirección IPv4 del nombre del dispositivo (como eth0 , lo , em0 , etc.)
- Seleccione Dispositivo IPv6 para seleccionar la dirección IPv6 del nombre del dispositivo (como eth0 , lo , em0 , etc.)
Esta propiedad se usa para habilitar la falsificación de IP. Anula la dirección IP local predeterminada para esta muestra. El host de JMeter debe tener varias direcciones IP (es decir, alias de IP, interfaces de red, dispositivos). El valor puede ser un nombre de host, una dirección IP o un dispositivo de interfaz de red como " eth0 " o " lo " o " wlan0 ".
Si se define la propiedad httpclient.localaddress , se usa para todas las solicitudes de HttpClient.
Los siguientes parámetros están disponibles solo para la solicitud HTTP de GraphQL :
Parámetros ¶
Manejo de parámetros:
para el método POST y PUT , si no hay ningún archivo para enviar y se omiten los nombres de los parámetros, el cuerpo se crea concatenando todos los valores de los parámetros. Tenga en cuenta que los valores se concatenan sin agregar ningún carácter de final de línea. Estos se pueden agregar usando la función __char() en los campos de valor. Esto permite enviar cuerpos arbitrarios. Los valores se codifican si se establece el indicador de codificación. Consulte también el Tipo MIME anterior sobre cómo puede controlar el encabezado de solicitud de tipo de contenido que se envía.
Para otros métodos, si falta el nombre del parámetro, se ignora el parámetro. Esto permite el uso de parámetros opcionales definidos por variables.
Tiene la opción de cambiar a la pestaña Datos del cuerpo cuando una solicitud solo tiene parámetros sin nombre (o ningún parámetro). Esta opción es útil en los siguientes casos (entre otros):
- Solicitud HTTP RPC de GWT
- Solicitud JSON REST HTTP
- Solicitud HTTP REST XML
- Solicitud SOAP HTTP
En el modo de datos del cuerpo , cada línea se enviará con CRLF adjunto, además de la última línea. Para enviar un CRLF después de la última línea de datos, solo asegúrese de que haya una línea vacía a continuación. (Esto no se puede ver, excepto observando si el cursor se puede colocar en la línea siguiente).



Manejo de métodos:
los métodos de solicitud GET , DELETE , POST , PUT y PATCH funcionan de manera similar, excepto que a partir de la versión 3.1, solo el método POST admite solicitudes de varias partes o carga de archivos. El cuerpo del método PUT y PATCH se debe proporcionar como uno de los siguientes:
- defina el cuerpo como un archivo con el campo Nombre de parámetro vacío; en cuyo caso se utiliza el tipo MIME como tipo de contenido
- definir el cuerpo como valor(es) de parámetro sin nombre
- use la pestaña Datos del cuerpo
Los métodos GET , DELETE y POST tienen una forma adicional de pasar parámetros mediante la pestaña Parámetros . GET , DELETE , PUT y PATCH requieren un tipo de contenido. Si no usa un archivo, adjunte un Administrador de encabezado a la muestra y defina el Tipo de contenido allí.
Respuestas de escaneo JMeter de recursos integrados. Utiliza la propiedad HTTPResponse.parsers , que es una lista de identificadores de analizadores, por ejemplo , htmlParser , cssParser y wmlParser . Para cada identificación encontrada, JMeter verifica dos propiedades más:
- id.types - una lista de tipos de contenido
- id.className : el analizador que se usará para extraer los recursos incrustados
Consulte el archivo jmeter.properties para conocer los detalles de la configuración. Si la propiedad HTTPResponse.parser no está configurada, JMeter vuelve al comportamiento anterior, es decir, solo se escanearán las respuestas de texto/html .
Emulando conexiones lentas:HttpClient4 y Java Sampler admiten la emulación de conexiones lentas; consulte las siguientes entradas en jmeter.properties :
# Definir caracteres por segundo > 0 para emular conexiones lentas #httpclient.socket.http.cps=0 #httpclient.socket.https.cps=0Sin embargo, la muestra de Java solo admite conexiones HTTPS lentas.
Cálculo del tamaño de la respuesta
La implementación de HttpClient4 incluye la sobrecarga en el tamaño del cuerpo de la respuesta, por lo que el valor puede ser mayor que la cantidad de bytes en el contenido de la respuesta.
Gestión de reintentos
De forma predeterminada, el reintento se ha establecido en 0 para las implementaciones HttpClient4 y Java, lo que significa que no se intenta ningún reintento.
Para HttpClient4, el recuento de reintentos se puede anular configurando la propiedad JMeter relevante, por ejemplo:
httpclient4.retrycount=3
httpclient4.request_sent_retry_enabled=true
http.java.sampler.retries=3
Nota: los certificados no se ajustan a las restricciones del algoritmo
Es posible que encuentre el siguiente error: java.security.cert.CertificateException: los certificados no se ajustan a las restricciones del algoritmo
si ejecuta una solicitud HTTPS en un sitio web con un certificado SSL (él mismo o uno de certificados SSL en su cadena de confianza) con un algoritmo de firma usando MD2 (como md2WithRSAEncryption ) o con un certificado SSL con un tamaño inferior a 1024 bits.
Este error está relacionado con una mayor seguridad en Java 8.
Para permitirle realizar su solicitud HTTPS, puede degradar la seguridad de su instalación de Java editando la propiedad Java jdk.certpath.disabledAlgorithms . Elimina el valor MD2 o la restricción de tamaño, según tu caso.
Esta propiedad está en este archivo:
JAVA_HOME/jre/lib/security/java.security
Consulte el error 56357 para obtener más detalles.
- Afirmación
- Creación de un plan de prueba web
- Creación de un plan de prueba web avanzado
- Administrador de autorización HTTP
- Administrador de cookies HTTP
- Administrador de encabezado HTTP
- Analizador de enlaces HTML
- Grabador de secuencias de comandos de prueba HTTP(S)
- Valores predeterminados de solicitud HTTP
- Solicitudes HTTP e ID de sesión: reescritura de URL
Solicitud JDBC ¶
Esta muestra le permite enviar una solicitud JDBC (una consulta SQL) a una base de datos.
Antes de usar esto, debe configurar un elemento de configuración de configuración de conexión JDBC
Si se proporciona la lista de nombres de variables, para cada fila devuelta por una instrucción Select, las variables se configuran con el valor de la columna correspondiente (si se proporciona un nombre de variable) y también se configura el recuento de filas. Por ejemplo, si la instrucción Select devuelve 2 filas de 3 columnas y la lista de variables es A,,C , se configurarán las siguientes variables:
A_#=2 (número de filas) A_1=columna 1, fila 1 A_2=columna 1, fila 2 C_#=2 (número de filas) C_1=columna 3, fila 1 C_2=columna 3, fila 2
Si la instrucción Select devuelve cero filas, las variables A_# y C_# se establecerían en 0 y no se establecería ninguna otra variable.
Las variables antiguas se borran si es necesario; por ejemplo, si la primera selección recupera seis filas y una segunda selección devuelve solo tres filas, se eliminarán las variables adicionales para las filas cuatro, cinco y seis.

Parámetros ¶
- Seleccionar estado de cuenta
- Declaración de actualización: use esto también para inserciones y eliminaciones
- Estado de cuenta exigible
- Declaración de selección preparada
- Declaración de actualización preparada: utilícela también para inserciones y eliminaciones
- Comprometerse
- Retroceder
- Confirmación automática (falso)
- Confirmación automática (verdadero)
- Editar: esta debería ser una referencia variable que se evalúe como una de las anteriores
- seleccione * de t_clientes donde id = 23
-
LLAME A SYSCS_UTIL.SYSCS_EXPORT_TABLE (nulo, ?, ?, nulo, nulo, nulo)
- Valores de parámetro: nombre de tabla , nombre de archivo
- Tipos de parámetros: VARCHAR , VARCHAR
La lista debe estar entre comillas dobles si alguno de los valores contiene una coma o comillas dobles, y cualquier comilla doble incrustada debe duplicarse, por ejemplo:
"Dbl-Quote: "" y Coma: ,"
Estos se definen como campos en la clase java.sql.Types , consulte por ejemplo:
Javadoc para java.sql.Types .
Si no se especifica, se asume " EN ", es decir, " FECHA " es lo mismo que " EN FECHA ".
Si el tipo no es uno de los campos que se encuentran en java.sql.Types , JMeter también acepta el número entero correspondiente, por ejemplo, dado que OracleTypes.CURSOR == -10 , puede usar " INOUT -10 ".
Debe haber tantos tipos como marcadores de posición en la instrucción.
columnValue = vars.getObject("resultObject").get(0).get("Nombre de columna");
- Almacenar como cadena (predeterminado): todas las variables en la lista Nombres de variables se almacenan como cadenas, no iterarán a través de un ResultSet cuando esté presente en la lista. Los CLOB se convertirán en cadenas. Los BLOB se convertirán en cadenas como si fueran una matriz de bytes codificada en UTF-8. Tanto CLOB como BLOB se cortarán después de jdbcsampler.max_retain_result_size bytes.
- Almacenar como objeto : las variables de tipo ResultSet en la lista de nombres de variables se almacenarán como objetos y se podrá acceder a ellas en pruebas/secuencias de comandos subsiguientes e iterar, no iterar a través del ResultSet . Los CLOB se manejarán como si se hubiera seleccionado Almacenar como cadena . Los BLOB se almacenarán como una matriz de bytes. Tanto los CLOB como los BLOB se cortarán después de jdbcsampler.max_retain_result_size bytes.
- Recuento de registros : las variables de los tipos de conjunto de resultados se repetirán mostrando el recuento de registros como resultado. Las variables se almacenarán como cadenas. Para BLOB s, se almacenará el tamaño del objeto.
Solicitud Java ¶
Esta muestra le permite controlar una clase Java que implementa la interfaz org.apache.jmeter.protocol.java.sampler.JavaSamplerClient . Al escribir su propia implementación de esta interfaz, puede usar JMeter para aprovechar múltiples subprocesos, controlar parámetros de entrada y recopilar datos.
El menú desplegable proporciona la lista de todas las implementaciones encontradas por JMeter en su classpath. Luego, los parámetros se pueden especificar en la tabla a continuación, según lo definido por su implementación. Se proporcionan dos ejemplos simples ( JavaTest y SleepTest ).
La muestra de ejemplo de JavaTest puede ser útil para comprobar los planes de prueba, ya que permite establecer valores en casi todos los campos. Estos pueden ser utilizados por Aserciones, etc. Los campos permiten el uso de variables, por lo que los valores de estos pueden verse fácilmente.

Parámetros ¶
Los siguientes parámetros se aplican a las implementaciones de SleepTest y JavaTest :
Parámetros ¶
el tiempo de sueño se calcula de la siguiente manera:
totalSleepTime = SleepTime + (System.currentTimeMillis() % SleepMask)
Los siguientes parámetros se aplican adicionalmente a la implementación de JavaTest :
Parámetros ¶
Solicitud LDAP ¶
Si va a enviar varias solicitudes al mismo servidor LDAP, considere usar un elemento de configuración de valores predeterminados de solicitud LDAP para que no tenga que ingresar la misma información para cada solicitud LDAP.
De la misma manera, el Elemento de configuración de inicio de sesión también se usa para el inicio de sesión y la contraseña.
Hay dos formas de crear casos de prueba para probar un servidor LDAP.
- Casos de prueba incorporados.
- Casos de prueba definidos por el usuario.
Hay cuatro escenarios de prueba para probar LDAP. Las pruebas se dan a continuación:
- Agregar prueba
- Prueba incorporada:
Esto agregará una entrada predefinida en el servidor LDAP y calculará el tiempo de ejecución. Después de la ejecución de la prueba, la entrada creada se eliminará del servidor LDAP.
- Prueba definida por el usuario:
Esto agregará la entrada en el servidor LDAP. El usuario debe ingresar todos los atributos en la tabla. Las entradas se recopilan de la tabla para agregar. Se calcula el tiempo de ejecución. La entrada creada no se eliminará después de la prueba.
- Prueba incorporada:
- Modificar prueba
- Prueba incorporada:
Esto creará primero una entrada predefinida, luego modificará la entrada creada en el servidor LDAP. Y calculará el tiempo de ejecución. Después de la ejecución de la prueba, la entrada creada se eliminará del servidor LDAP.
- Prueba definida por el usuario:
Esto modificará la entrada en el servidor LDAP. El usuario debe ingresar todos los atributos en la tabla. Las entradas se recopilan de la tabla para modificar. Se calcula el tiempo de ejecución. La entrada no se eliminará del servidor LDAP.
- Prueba incorporada:
- Prueba de búsqueda
- Prueba incorporada:
Esto creará la entrada primero, luego buscará si los atributos están disponibles. Calcula el tiempo de ejecución de la consulta de búsqueda. Al final de la ejecución, la entrada creada se eliminará del servidor LDAP.
- Prueba definida por el usuario:
Esto buscará la entrada definida por el usuario (filtro de búsqueda) en la base de búsqueda (nuevamente, definida por el usuario). Las entradas deben estar disponibles en el servidor LDAP. Se calcula el tiempo de ejecución.
- Prueba incorporada:
- Eliminar prueba
- Prueba incorporada:
Esto creará primero una entrada predefinida y luego se eliminará del servidor LDAP. Se calcula el tiempo de ejecución.
- Prueba definida por el usuario:
Esto eliminará la entrada definida por el usuario en el servidor LDAP. Las entradas deben estar disponibles en el servidor LDAP. Se calcula el tiempo de ejecución.
- Prueba incorporada:
Parámetros ¶
Solicitud extendida LDAP ¶
Si va a enviar varias solicitudes al mismo servidor LDAP, considere usar un elemento de configuración predeterminado de solicitud extendida de LDAP para que no tenga que ingresar la misma información para cada solicitud LDAP.

Hay nueve operaciones de prueba definidas. Estas operaciones se dan a continuación:
- Enlace de hilo
-
Cualquier solicitud LDAP es parte de una sesión LDAP, por lo que lo primero que se debe hacer es iniciar una sesión en el servidor LDAP. Para iniciar esta sesión se utiliza un enlace de subprocesos, que es igual a la operación " bind " de LDAP. Se solicita al usuario que proporcione un nombre de usuario (Nombre distinguido) y una contraseña , que se utilizará para iniciar una sesión. Cuando no se especifica ninguna contraseña o se especifica una contraseña incorrecta, se inicia una sesión anónima. Tenga cuidado, omitir la contraseña no fallará esta prueba, una contraseña incorrecta sí lo hará. (Nota: esto se almacena sin cifrar en el plan de prueba)
Parámetros
AtributoDescripciónRequeridoNombreNombre descriptivo de esta muestra que se muestra en el árbol.NoNombre del servidorEl nombre (o dirección IP) del servidor LDAP.SíPuertoEl número de puerto que escucha el servidor LDAP. Si esto se omite, JMeter asume que el servidor LDAP está escuchando en el puerto predeterminado (389).NoDNEl nombre distinguido del objeto base que se usará para cualquier operación posterior. Se puede utilizar como punto de partida para todas las operaciones. ¡No puede iniciar ninguna operación en un nivel superior a este DN!NoNombre de usuarioNombre distinguido completo del usuario con el que desea enlazar.NoClaveContraseña para el usuario anterior. Si se omite, dará como resultado un enlace anónimo. Si es incorrecto, el muestreador devolverá un error y volverá a un enlace anónimo. (Nota: esto se almacena sin cifrar en el plan de prueba)NoTiempo de espera de conexión (en milisegundos)Tiempo de espera para la conexión, si se excede la conexión será abortadaNoUsar protocolo LDAP seguroUtilice el esquema ldaps:// en lugar de ldap://NoConfiar en todos los certificadosConfiar en todos los certificados, solo se usa si se marca Usar protocolo LDAP seguroNo - Desvincular hilo
-
Esta es simplemente la operación para finalizar una sesión. Es igual a la operación " desvincular " de LDAP.
Parámetros
AtributoDescripciónRequeridoNombreNombre descriptivo de esta muestra que se muestra en el árbol.No - Enlace/desenlace simple
-
Esta es una combinación de las operaciones LDAP " bind " y " unbind ". Se puede utilizar para una solicitud de autenticación/verificación de contraseña para cualquier usuario. Abrirá una nueva sesión, solo para verificar la validez de la combinación usuario/contraseña, y finalizará la sesión nuevamente.
Parámetros
AtributoDescripciónRequeridoNombreNombre descriptivo de esta muestra que se muestra en el árbol.NoNombre de usuarioNombre distinguido completo del usuario con el que desea enlazar.SíClaveContraseña para el usuario anterior. Si se omite, dará como resultado un enlace anónimo. Si es incorrecto, el muestreador devolverá un error. (Nota: esto se almacena sin cifrar en el plan de prueba)No - Cambiar nombre de entrada
-
Esta es la operación " moddn " de LDAP. Puede usarse para cambiar el nombre de una entrada, pero también para mover una entrada o un subárbol completo a un lugar diferente en el árbol LDAP.
Parámetros
AtributoDescripciónRequeridoNombreNombre descriptivo de esta muestra que se muestra en el árbol.NoNombre de la entrada anteriorEl nombre distinguido actual del objeto que desea cambiar de nombre o mover, en relación con el DN dado en la operación de vinculación de subprocesos.SíNuevo nombre distinguidoEl nuevo nombre distinguido del objeto que desea cambiar de nombre o mover, en relación con el DN dado en la operación de vinculación de subprocesos.Sí - Agregar prueba
-
Esta es la operación " añadir " de LDAP . Se puede usar para agregar cualquier tipo de objeto al servidor LDAP.
Parámetros
AtributoDescripciónRequeridoNombreNombre descriptivo de esta muestra que se muestra en el árbol.NoDN de entradaNombre distinguido del objeto que desea agregar, en relación con el DN dado en la operación de vinculación de subprocesos.SíAgregar pruebaUna lista de atributos y sus valores que desea utilizar para el objeto. Si necesita agregar un atributo de valor múltiple, debe agregar el mismo atributo con sus respectivos valores varias veces a la lista.Sí - Eliminar prueba
-
Esta es la operación de " eliminación " de LDAP, se puede usar para eliminar un objeto del árbol LDAP
Parámetros
AtributoDescripciónRequeridoNombreNombre descriptivo de esta muestra que se muestra en el árbol.NoBorrarNombre distinguido del objeto que desea eliminar, en relación con el DN dado en la operación de vinculación de subprocesos.Sí - Prueba de búsqueda
-
Esta es la operación de " búsqueda " de LDAP y se utilizará para definir búsquedas.
Parámetros
AtributoDescripciónRequeridoNombreNombre descriptivo de esta muestra que se muestra en el árbol.NoBase de búsquedaNombre distinguido del subárbol en el que desea que busque su búsqueda, en relación con el DN dado en la operación de vinculación de subprocesos.NoFiltro de búsquedasearchfilter, debe especificarse en la sintaxis LDAP.SíAlcanceUse 0 para baseobject-, 1 para onelevel- y 2 para una búsqueda de subárbol. (Predeterminado= 0 )NoLímite de tamañoEspecifique el número máximo de resultados que desea recibir del servidor. (predeterminado = 0 , lo que significa que no hay límite). Cuando la muestra alcanza el número máximo de resultados, fallará con el código de error 4NoLímite de tiempoEspecifique la cantidad máxima de tiempo (cpu) (en milisegundos) que el servidor puede dedicar a su búsqueda. Ojo, esto no dice nada sobre el tiempo de respuesta. (el valor predeterminado es 0 , lo que significa que no hay límite)NoAtributosEspecifique los atributos que desea que se devuelvan, separados por un punto y coma. Un campo vacío devolverá todos los atributosNoObjeto devueltoSi el objeto se devolverá ( verdadero ) o no ( falso ). Predeterminado = falsoNoAlias de desreferenciaSi es verdadero , eliminará la referencia a los alias, si es falso , no los seguirá (predeterminado = falso )No¿Analizar los resultados de la búsqueda?Si es verdadero , los resultados de la búsqueda se agregarán a los datos de respuesta. Si es false , se agregará un marcador, ya sea que se encuentren resultados o no, a los datos de respuesta.No - Prueba de modificación
-
Esta es la operación de " modificación " de LDAP . Se puede utilizar para modificar un objeto. Se puede usar para agregar, eliminar o reemplazar valores de un atributo.
Parámetros
AtributoDescripciónRequeridoNombreNombre descriptivo de esta muestra que se muestra en el árbol.NoNombre de la entradaNombre distinguido del objeto que desea modificar, en relación con el DN dado en la operación de vinculación de subprocesosSíPrueba de modificaciónEl atributo-valor-opCode se triplica.
El código de operación puede ser cualquier código de operación LDAP válido ( agregar , eliminar , eliminar o reemplazar ).
Si no especifica un valor con una operación de eliminación , se eliminarán todos los valores del atributo dado.
Si especifica un valor en una operación de eliminación , solo se eliminará el valor dado.
Si este valor no existe, el muestreador fallará la prueba.Sí - Comparar
-
Esta es la operación de " comparación " de LDAP . Puede usarse para comparar el valor de un atributo dado con algún valor ya conocido. En realidad, esto se usa principalmente para verificar si una persona determinada es miembro de algún grupo. En tal caso, puede comparar el DN del usuario como un valor dado, con los valores en el atributo " miembro " de un objeto del tipo groupOfNames . Si la operación de comparación falla, esta prueba falla con el código de error 49 .
Parámetros
AtributoDescripciónRequeridoNombreNombre descriptivo de esta muestra que se muestra en el árbol.NoDN de entradaEl nombre distinguido actual del objeto del que desea comparar un atributo, en relación con el DN dado en la operación de vinculación de subprocesos.SíComparar filtroEn la forma " atributo=valor "Sí
Muestra de registro de acceso ¶
AccessLogSampler fue diseñado para leer registros de acceso y generar solicitudes http. Para aquellos que no estén familiarizados con el registro de acceso, es el registro que el servidor web mantiene de cada solicitud que acepta. Esto significa cada imagen, archivo CSS, archivo JavaScript, archivo html,...
Tomcat usa el formato común para los registros de acceso. Esto significa que cualquier servidor web que use el formato de registro común puede usar AccessLogSampler. Los servidores que usan un formato de registro común incluyen: Tomcat, Resin, Weblogic y SunOne. El formato de registro común se ve así:
127.0.0.1 - - [21/oct/2003:05:37:21 -0500] "GET /index.jsp?%2Findex.jsp= HTTP/1.1" 200 8343
Para el futuro, sería bueno filtrar las entradas que no tienen un código de respuesta de 200 . Extender la muestra debería ser bastante simple. Hay dos interfaces que tienes que implementar:
- org.apache.jmeter.protocol.http.util.accesslog.LogParser
- org.apache.jmeter.protocol.http.util.accesslog.Generator
La implementación actual de AccessLogSampler usa el generador para crear un nuevo HTTPSampler. AccessLogSampler establece el nombre del servidor, el puerto y las imágenes obtenidas. A continuación, se llama al analizador con el número entero 1 , diciéndole que analice una entrada. Después de eso, se llama a HTTPSampler.sample() para realizar la solicitud.
muestra = (HTTPSampler) GENERADOR.generateRequest(); muestra.setDomain(this.getDomain()); muestra.setPort(this.getPort()); muestra.setImageParser(this.isImageParser()); PARSER.parse(1); res = muestra.muestra(); res.setSampleLabel(muestra.toString());Los métodos requeridos en LogParser son:
- setGenerator(Generador)
- analizar (int)
Las clases que implementan la interfaz de Generator deben proporcionar una implementación concreta para todos los métodos. Para ver un ejemplo de cómo implementar cualquiera de las interfaces, consulte StandardGenerator y TCLogParser .

(Código Beta)
Parámetros ¶
El TCLogParser procesa el registro de acceso de forma independiente para cada subproceso. SharedTCLogParser y OrderPreservingLogParser comparten el acceso al archivo, es decir, cada subproceso obtiene la siguiente entrada en el registro.
El SessionFilter está diseñado para manejar cookies a través de subprocesos. No filtra ninguna entrada, pero modifica el administrador de cookies para que las cookies para una IP dada sean procesadas por un solo hilo a la vez. Si dos subprocesos intentan procesar muestras desde la misma dirección IP del cliente, uno se verá obligado a esperar hasta que el otro haya finalizado.
LogFilter está diseñado para permitir que las entradas del registro de acceso se filtren por nombre de archivo y expresión regular, así como para permitir el reemplazo de extensiones de archivo. Sin embargo, actualmente no es posible configurar esto a través de la GUI, por lo que realmente no se puede usar.
Muestreador BeanShell ¶
Esta muestra le permite escribir una muestra utilizando el lenguaje de secuencias de comandos BeanShell.
Para obtener detalles completos sobre el uso de BeanShell, consulte el sitio web de BeanShell.
El elemento de prueba admite los métodos de interfaz ThreadListener y TestListener . Estos deben definirse en el archivo de inicialización. Consulte el archivo BeanShellListeners.bshrc para ver definiciones de ejemplo.
El muestreador BeanShell también es compatible con la interfaz interrumpible . El método interrupt() se puede definir en el script o en el archivo de inicio.

Parámetros ¶
- Parámetros
- cadena que contiene los parámetros como una sola variable
- bsh.args
- Matriz de cadenas que contiene parámetros, dividida en espacios en blanco
Si se define la propiedad " beanshell.sampler.init ", se pasa al intérprete como el nombre de un archivo fuente. Esto se puede utilizar para definir métodos y variables comunes. Hay un archivo de inicio de muestra en el directorio bin: BeanShellSampler.bshrc .
Si se proporciona un archivo de secuencia de comandos, se utilizará, de lo contrario, se utilizará la secuencia de comandos.
BeanShell actualmente no es compatible con la sintaxis de Java 5, como los genéricos y el bucle for mejorado.
Antes de invocar el script, se configuran algunas variables en el intérprete BeanShell:
El contenido del campo Parámetros se pone en la variable " Parámetros ". La cadena también se divide en tokens separados utilizando un solo espacio como separador, y la lista resultante se almacena en la matriz de cadenas bsh.args .
La lista completa de variables BeanShell configuradas es la siguiente:
- registro - el registrador
- Etiqueta : la etiqueta del muestreador
- FileName : el nombre del archivo, si lo hay
- Parámetros : texto del campo Parámetros
- bsh.args - los parámetros, divididos como se describe arriba
- SampleResult - puntero al SampleResult actual
- El código de respuesta predeterminado es 200
- El valor predeterminado de ResponseMessage es " OK "
- IsSuccess por defecto es verdadero
- ctx - JMeterContext
-
vars - JMeterVariables - por ejemplo
vars.get("VAR1"); vars.put("VAR2","valor"); vars.remove("VAR3"); vars.putObject("OBJ1",nuevo Objeto()); -
accesorios - JMeterProperties (clase java.util.Properties ) - por ejemplo
props.get("INICIO.HMS"); props.put("PROP1","1234");
Cuando se completa la secuencia de comandos, se devuelve el control a Sampler y copia el contenido de las siguientes variables de secuencia de comandos en las variables correspondientes en SampleResult :
- Código de respuesta - por ejemplo 200
- Mensaje de respuesta : por ejemplo, " OK "
- IsSuccess - verdadero o falso
SampleResult ResponseData se establece a partir del valor de retorno del script. Si el script devuelve un valor nulo, puede establecer la respuesta directamente mediante el método SampleResult.setResponseData(data) , donde data es una cadena o una matriz de bytes. El tipo de datos predeterminado es " texto ", pero se puede establecer en binario mediante el método SampleResult.setDataType(SampleResult.BINARY) .
La variable SampleResult le da al script acceso completo a todos los campos y métodos en SampleResult . Por ejemplo, el script tiene acceso a los métodos setStopThread(boolean) y setStopTest(boolean) . Aquí hay un script de ejemplo simple (¡no muy útil!):
if (bsh.args[0].equalsIgnoreCase("StopThread")) {
log.info("¡Detener subproceso detectado!");
SampleResult.setStopThread(verdadero);
}
devuelve "Datos de la muestra con Etiqueta "+Etiqueta;
//o
SampleResult.setResponseData("Mis datos");
devolver nulo;
Otro ejemplo:
asegúrese de que la propiedad beanshell.sampler.init=BeanShellSampler.bshrc esté definida en jmeter.properties . El siguiente script mostrará los valores de todas las variables en el campo ResponseData :
devuelve obtenerVariables();
Para obtener detalles sobre los métodos disponibles para las distintas clases ( JMeterVariables , SampleResult , etc.), consulte el Javadoc o el código fuente. Sin embargo, tenga en cuenta que el mal uso de cualquier método puede causar fallas sutiles que pueden ser difíciles de encontrar.
Muestreador JSR223 ¶
El muestreador JSR223 permite que se use el código de secuencia de comandos JSR223 para realizar una muestra o algún cálculo necesario para crear/actualizar variables.
MuestraResultado.setIgnorar();Esta convocatoria tendrá el siguiente impacto:
- SampleResult no se entregará a SampleListeners como View Results Tree, Summariser...
- SampleResult no se evaluará en aserciones ni en postprocesadores
- SampleResult se evaluará para calcular el estado de la última muestra (${JMeterThread.last_sample_ok}) y ThreadGroup "Acción a tomar después de un error de Sampler" (desde JMeter 5.4)
Los elementos de prueba JSR223 tienen una función (compilación) que puede aumentar significativamente el rendimiento. Para beneficiarse de esta característica:
- Utilice archivos de secuencias de comandos en lugar de insertarlos. Esto hará que JMeter los compile si esta función está disponible en ScriptEngine y los almacene en caché.
- O Use Script Text y marque Cache compilated script si está disponible .
Al usar esta función, asegúrese de que su código de secuencia de comandos no use variables de JMeter o llamadas a funciones de JMeter directamente en el código de secuencia de comandos, ya que el almacenamiento en caché solo almacenaría en caché el primer reemplazo. En su lugar, utilice parámetros de secuencia de comandos.Para beneficiarse del almacenamiento en caché y la compilación, el motor de lenguaje utilizado para las secuencias de comandos debe implementar la interfaz compilable JSR223 (Groovy es uno de estos, java, beanshell y javascript no lo son)Cuando utilice Groovy como lenguaje de secuencias de comandos y no verifique la secuencia de comandos compilada de Cache si está disponible (aunque se recomienda el almacenamiento en caché), debe establecer esta propiedad JVM -Dgroovy.use.classvalue=true debido a una fuga de Groovy Memory a partir de la versión 2.4.6, consulte:
jsr223.compiled_scripts_cache_size=100

props.get("INICIO.HMS");
props.put("PROP1","1234");
Parámetros ¶
Tenga en cuenta que algunos lenguajes como Velocity pueden usar una sintaxis diferente para las variables JSR223, por ejemplo
$log.debug("Hola " + $vars.get("a"));para Velocidad.
Si se proporciona un archivo de secuencia de comandos, se utilizará, de lo contrario, se utilizará la secuencia de comandos.
Antes de invocar el script, se configuran algunas variables. Tenga en cuenta que estas son variables JSR223, es decir, se pueden usar directamente en el script.
- registro - el registrador
- Etiqueta : la etiqueta del muestreador
- FileName : el nombre del archivo, si lo hay
- Parámetros : texto del campo Parámetros
- args - los parámetros, divididos como se describe arriba
- SampleResult - puntero al SampleResult actual
- sampler - ( Sampler ) - puntero al Sampler actual
- ctx - JMeterContext
-
vars - JMeterVariables - por ejemplo
vars.get("VAR1"); vars.put("VAR2","valor"); vars.remove("VAR3"); vars.putObject("OBJ1",nuevo Objeto()); -
accesorios - JMeterProperties (clase java.util.Properties ) - por ejemplo
props.get("INICIO.HMS"); props.put("PROP1","1234"); - OUT - System.out - por ejemplo, OUT.println("mensaje")
SampleResult ResponseData se establece a partir del valor de retorno del script. Si la secuencia de comandos devuelve nulo , puede establecer la respuesta directamente mediante el método SampleResult.setResponseData(data) , donde los datos son una cadena o una matriz de bytes. El tipo de datos predeterminado es " texto ", pero se puede establecer en binario mediante el método SampleResult.setDataType(SampleResult.BINARY) .
La variable SampleResult le da al script acceso total a todos los campos y métodos en SampleResult. Por ejemplo, el script tiene acceso a los métodos setStopThread(boolean) y setStopTest(boolean) .
A diferencia de BeanShell Sampler, JSR223 Sampler no establece el código de respuesta , el mensaje de respuesta y el estado de la muestra a través de variables de script. Actualmente, la única forma de cambiarlos es a través de los métodos SampleResult :
- SampleResult.setSuccessful(verdadero/falso)
- SampleResult.setResponseCode("código")
- SampleResult.setResponseMessage("mensaje")
Muestreador de TCP ¶
TCP Sampler abre una conexión TCP/IP al servidor especificado. Luego envía el texto y espera una respuesta.
Si se selecciona " Reutilizar conexión ", las conexiones se comparten entre Samplers en el mismo subproceso, siempre que se utilicen exactamente la misma cadena de nombre de host y puerto. Diferentes combinaciones de hosts/puertos utilizarán diferentes conexiones, al igual que diferentes subprocesos. Si se seleccionan " Reutilizar conexión " y " Cerrar conexión ", el zócalo se cerrará después de ejecutar el muestreador. En la siguiente muestra, se creará otro zócalo. Es posible que desee cerrar un zócalo al final de cada bucle de hilo.
Si se detecta un error, o no se selecciona " Reutilizar conexión ", el socket se cierra. Se reabrirá otro socket en la siguiente muestra.
Las siguientes propiedades se pueden utilizar para controlar su funcionamiento:
- tcp.estado.prefijo
- texto que precede a un número de estado
- tcp.status.sufijo
- texto que sigue a un número de estado
- tcp.estado.propiedades
- nombre del archivo de propiedades para convertir códigos de estado en mensajes
- controlador tcp
- Nombre de la clase del controlador TCP (predeterminado TCPClientImpl ): solo se usa si no se especifica en la GUI
Los usuarios pueden proporcionar su propia implementación. La clase debe extender org.apache.jmeter.protocol.tcp.sampler.TCPClient .
Actualmente se proporcionan las siguientes implementaciones.
- TCPClientImpl
- BinaryTCPClientImpl
- LongitudPrefijadoBinarioTCPClientImpl
- TCPClientImpl
- Esta implementación es bastante básica. Al leer la respuesta, lee hasta el final del byte de línea, si esto se define configurando la propiedad tcp.eolByte , de lo contrario, hasta el final del flujo de entrada. Puede controlar la codificación del conjunto de caracteres configurando tcp.charset , que tendrá la codificación predeterminada de la plataforma.
- BinaryTCPClientImpl
- Esta implementación convierte la entrada de la GUI, que debe ser una cadena codificada en hexadecimal, en binaria y realiza lo contrario al leer la respuesta. Al leer la respuesta, lee hasta el final del byte del mensaje, si esto se define configurando la propiedad tcp.BinaryTCPClient.eomByte , de lo contrario, hasta el final del flujo de entrada.
- LongitudPrefijadoBinarioTCPClientImpl
- Esta implementación amplía BinaryTCPClientImpl prefijando los datos del mensaje binario con un byte de longitud binaria. El prefijo de longitud por defecto es de 2 bytes. Esto se puede cambiar configurando la propiedad tcp.binarylength.prefix.length .
- Manejo de tiempos de espera
- Si se establece el tiempo de espera, la lectura finalizará cuando expire. Entonces, si está utilizando un eolByte / eomByte , asegúrese de que el tiempo de espera sea lo suficientemente largo, de lo contrario, la lectura terminará antes de tiempo.
- Manejo de respuestas
-
Si se define tcp.status.prefix , se busca en el mensaje de respuesta el texto que sigue hasta el sufijo. Si se encuentra algún texto de este tipo, se utiliza para establecer el código de respuesta. A continuación, el mensaje de respuesta se obtiene del archivo de propiedades (si se proporciona).
Los códigos de respuesta en el rango " 400 "-" 499 " y " 500 "-" 599 " actualmente se consideran fallas; todos los demás tienen éxito. [¡Esto debe hacerse configurable!]Uso de pre y sufijo ¶Por ejemplo, si el prefijo = " [ " y el sufijo = " ] ", entonces la siguiente respuesta:
[J28] XI123,23, GBP, CR
tendría el código de respuesta J28 .
Los enchufes se desconectan al final de una prueba.

Parámetros ¶
Publicador JMS ¶
JMS Publisher publicará mensajes en un destino determinado (tema/cola). Para aquellos que no están familiarizados con JMS, es la especificación J2EE para mensajería. Existen numerosos servidores JMS en el mercado y varias opciones de código abierto.

Parámetros ¶
- Desde el archivo
- significa que el archivo al que se hace referencia será leído y reutilizado por todas las muestras. Si el nombre del archivo cambia, se vuelve a cargar desde JMeter 3.0
- Archivo aleatorio de la carpeta especificada a continuación
- significa que se seleccionará un archivo aleatorio de la carpeta especificada a continuación, esta carpeta debe contener archivos con extensión .dat para mensajes de bytes o archivos con extensión .txt u .obj para mensajes de objeto o de texto
- área de texto
- El mensaje a usar para mensaje de texto u objeto
- CRUDO :
- No hay soporte variable del archivo y cárguelo con el juego de caracteres predeterminado del sistema.
- PREDETERMINADO :
- Cargue el archivo con la codificación predeterminada del sistema, excepto XML, que se basa en el prólogo XML. Si el archivo contiene variables, se procesarán.
- Juego de caracteres estándar :
- La codificación especificada (válida o no) se utiliza para leer el archivo y procesar variables
Para el tipo MapMessage, JMeter lee la fuente como líneas de texto. Cada línea debe tener 3 campos, delimitados por comas. Los campos son:
- Nombre de la entrada
- Nombre de la clase de objeto, por ejemplo, " String " (supone el paquete java.lang si no se especifica)
- Valor de cadena de objeto
nombre,Cadena,Ejemplo tamaño,Entero,1234
- Coloque el JAR que contiene su objeto y sus dependencias en la carpeta jmeter_home/lib/
- Serialice su objeto como XML usando XStream
- Coloque el resultado en un archivo con el sufijo .txt o .obj o coloque el contenido XML directamente en el área de texto
La siguiente tabla muestra algunos valores que pueden ser útiles al configurar JMS:
| Apache Active MQ | Valores) | Comentario |
|---|---|---|
| Fábrica de contexto | org.apache.activemq.jndi.ActiveMQInitialContextFactory | . |
| URL del proveedor | vm://hostlocal | |
| URL del proveedor | vm:(intermediario:(vm://localhost)?persistente=falso) | Deshabilitar persistencia |
| Referencia de cola | colas dinámicas/NOMBRE DE LA COLA | Definir dinámicamente el NOMBRE DE LA COLA a JNDI |
| Referencia del tema | Temas dinámicos/NOMBRE DEL TEMA | Definir dinámicamente TOPICNAME a JNDI |
Suscriptor JMS ¶
El suscriptor de JMS se suscribirá a los mensajes en un destino determinado (tema o cola). Para aquellos que no están familiarizados con JMS, es la especificación J2EE para mensajería. Existen numerosos servidores JMS en el mercado y varias opciones de código abierto.

Parámetros ¶
- ConsumidorMensaje.recibir()
- llama a receive() para cada mensaje solicitado. Conserva la conexión entre muestras, pero no obtiene mensajes a menos que el muestreador esté activo. Esto se adapta mejor a las suscripciones de Queue.
- EscuchaMensaje.onMessage()
- establece un Listener que almacena todos los mensajes entrantes en una cola. El oyente permanece activo después de que se completa la muestra. Esto se adapta mejor a las suscripciones de temas.
JMS punto a punto ¶
Este muestreador envía y, opcionalmente, recibe mensajes JMS a través de conexiones punto a punto (colas). Es diferente de los mensajes de publicación/suscripción y generalmente se usa para manejar transacciones.
request_only normalmente se utilizará para poner carga en un sistema JMS.
request_reply se utilizará cuando desee probar el tiempo de respuesta de un servicio JMS que procesa los mensajes enviados a la cola de solicitudes, ya que este modo esperará la respuesta en la cola de respuestas enviada por este servicio.
examinar devuelve la profundidad actual de la cola, es decir, el número de mensajes en la cola.
read lee un mensaje de la cola (si lo hay).
clear borra la cola, es decir, elimina todos los mensajes de la cola.
JMeter usa las propiedades java.naming.security.[principal|credentials] , si están presentes, al crear la conexión de cola. Si no se desea este comportamiento, establezca la propiedad JMeter JMSSampler.useSecurity.properties=false

Parámetros ¶
- Solo solicitud
- solo enviará mensajes y no monitoreará las respuestas. Como tal, se puede utilizar para poner carga en un sistema.
- Solicitar respuesta
- enviará mensajes y monitoreará las respuestas que reciba. El comportamiento depende del valor de JNDI Name Reply Queue. Si la Cola de respuesta de nombre JNDI tiene un valor, esta cola se utiliza para supervisar los resultados. La coincidencia de solicitud y respuesta se realiza con la identificación del mensaje de la solicitud y la identificación de correlación de la respuesta. Si la cola de respuesta de nombre JNDI está vacía, se utilizarán colas temporales para la comunicación entre el solicitante y el servidor. Esto es muy diferente de la cola de respuesta fija. Con colas temporales, el hilo de envío se bloqueará hasta que se reciba el mensaje de respuesta. Con el modo de respuesta de solicitud , debe tener un servidor que escuche los mensajes enviados a la cola de solicitudes y envíe respuestas a la cola a la que hace referencia message.getJMSReplyTo() .
- Leer
- leerá un mensaje de una cola saliente que no tiene oyentes adjuntos. Esto puede ser conveniente para fines de prueba. Este método se puede usar si necesita manejar colas sin un archivo de enlace (en caso de que se use la biblioteca jmeter-jms-skip-jndi), que solo funciona con el muestreador punto a punto JMS. En caso de que se utilicen archivos vinculantes, también se puede utilizar el muestreador de suscriptor JMS para leer desde una cola.
- Navegar
- determinará la profundidad actual de la cola sin eliminar mensajes de la cola, devolviendo la cantidad de mensajes en la cola.
- Claro
- borrará la cola, es decir, eliminará todos los mensajes de la cola.
- Usar ID de mensaje de solicitud
- si se selecciona, se utilizará la solicitud JMSMessageID; de lo contrario, se utilizará la solicitud JMSCorrelationID. En este último caso, la identificación de correlación debe especificarse en la solicitud.
- Usar ID de mensaje de respuesta
- si se selecciona, se utilizará la respuesta JMSMessageID; de lo contrario, se utilizará la respuesta JMSCorrelationID.
- Patrón de ID de correlación JMS
- es decir, haga coincidir la solicitud y la respuesta en sus ID de correlación => anule la selección de ambas casillas de verificación y proporcione una ID de correlación.
- Patrón de ID de mensaje JMS
- es decir, haga coincidir la identificación del mensaje de solicitud con la identificación de correlación de respuesta => seleccione "Usar identificación de mensaje de solicitud" únicamente.
Solicitud JUnit ¶
- en lugar de usar la interfaz de prueba de JMeter, escanea los archivos jar en busca de clases que extiendan la clase TestCase de JUnit . Eso incluye cualquier clase o subclase.
- Los archivos jar de prueba JUnit deben colocarse en jmeter/lib/junit en lugar del directorio /lib . También puede usar la propiedad " user.classpath " para especificar dónde buscar las clases de TestCase .
- JUnit sampler no usa pares de nombre/valor para la configuración como Java Request . El muestreador asume que setUp y tearDown configurarán la prueba correctamente.
- El muestreador mide el tiempo transcurrido solo para el método de prueba y no incluye configuración ni desmontaje .
- Cada vez que se llama al método de prueba, JMeter pasará el resultado a los oyentes.
- El soporte para oneTimeSetUp y oneTimeTearDown se realiza como un método. Dado que JMeter tiene subprocesos múltiples, no podemos llamar a oneTimeSetUp / oneTimeTearDown de la misma manera que lo hace Maven.
- El muestreador informa las excepciones inesperadas como errores. Existen algunas diferencias importantes entre los ejecutores de pruebas JUnit estándar y la implementación de JMeter. En lugar de crear una nueva instancia de la clase para cada prueba, JMeter crea 1 instancia por muestra y la reutiliza. Esto se puede cambiar con la casilla de verificación " Crear una nueva instancia por muestra ".
clase pública myTestCase {
myTestCase público () {}
}
Constructor de cadenas:
clase pública myTestCase {
public myTestCase(Texto de cadena) {
super(texto);
}
}
Reglas generales
Si usa setUp y tearDown , asegúrese de que los métodos se declaren públicos. Si no lo hace, es posible que la prueba no se ejecute correctamente.Aquí hay algunas pautas generales para escribir pruebas JUnit para que funcionen bien con JMeter. Dado que JMeter ejecuta subprocesos múltiples, es importante tener en cuenta ciertas cosas.
- Escriba los métodos setUp y tearDown para que sean seguros para subprocesos. Esto generalmente significa evitar el uso de miembros estáticos.
- Haga que los métodos de prueba sean unidades discretas de trabajo y no largas secuencias de acciones. Al mantener el método de prueba en una operación discreta, se facilita la combinación de métodos de prueba para crear nuevos planes de prueba.
- Evite hacer que los métodos de prueba dependan unos de otros. Dado que JMeter permite la secuenciación arbitraria de métodos de prueba, el comportamiento del tiempo de ejecución es diferente al comportamiento predeterminado de JUnit.
- Si un método de prueba es configurable, tenga cuidado con el lugar donde se almacenan las propiedades. Se recomienda leer las propiedades del archivo Jar.
- Cada muestra crea una instancia de la clase de prueba, así que escribe tu prueba para que la configuración ocurra en oneTimeSetUp y oneTimeTearDown .

Parámetros ¶
Se reconocen las siguientes anotaciones JUnit4:
- @Prueba
- Se utiliza para encontrar métodos de prueba y clases. Se admiten los atributos " esperado " y " tiempo de espera ".
- @Antes
- tratado igual que setUp() en JUnit3
- @Después
- tratado igual que tearDown() en JUnit3
- @Antes de la clase, @Después de la clase
- tratados como métodos de prueba para que puedan ejecutarse de forma independiente según sea necesario
Muestra de lector de correo ¶
Mail Reader Sampler puede leer (y opcionalmente borrar) mensajes de correo usando los protocolos POP3(S) o IMAP(S).

Parámetros ¶
En su defecto, contra el directorio que contiene el script de prueba (archivo JMX).
Los mensajes se almacenan como submuestras del muestreador principal. Las partes del mensaje de varias partes se almacenan como submuestras del mensaje.
Manejo especial para el protocolo " archivo
":
el proveedor de archivos JavaMail se puede usar para leer mensajes sin procesar de archivos. El campo del servidor se utiliza para especificar la ruta al padre de la carpeta . Los archivos de mensajes individuales deben almacenarse con el nombre n.msg , donde n es el número de mensaje. Alternativamente, el campo del servidor puede ser el nombre de un archivo que contiene un solo mensaje. La implementación actual es bastante básica y está pensada principalmente para fines de depuración.
Acción de control de flujo (era: Acción de prueba) ¶
Este sampler también puede ser útil en conjunto con Transaction Controller, ya que permite incluir pausas sin necesidad de generar una muestra. Para demoras variables, establezca el tiempo de pausa en cero y agregue un temporizador como elemento secundario.
La acción " Detener " detiene el subproceso o la prueba después de completar las muestras que están en curso. La acción " Detener ahora " detiene la prueba sin esperar a que se completen las muestras; interrumpirá cualquier muestra activa. Si algunos subprocesos no se detienen dentro del límite de tiempo de 5 segundos, se mostrará un mensaje en el modo GUI. Puede intentar usar el comando Detener para ver si esto detendrá los subprocesos, pero si no, debe salir de JMeter. En el modo CLI, JMeter se cerrará si algunos subprocesos no se detienen dentro del límite de tiempo de 5 segundos.

Parámetros ¶
Muestra SMTP ¶
SMTP Sampler puede enviar mensajes de correo utilizando el protocolo SMTP/SMTPS. Es posible establecer protocolos de seguridad para la conexión (SSL y TLS), así como autenticación de usuarios. Si se utiliza un protocolo de seguridad, se realizará una verificación en el certificado del servidor.
Hay dos alternativas disponibles para manejar esta verificación:
- Confiar en todos los certificados
- Esto ignorará la verificación de la cadena de certificados.
- Usar un almacén de confianza local
- Con esta opción, la cadena de certificados se validará con el archivo del almacén de confianza local.

Parámetros ¶
En su defecto, contra el directorio que contiene el script de prueba (archivo JMX).
Muestreador de procesos del sistema operativo ¶
OS Process Sampler es una muestra que se puede usar para ejecutar comandos en la máquina local.
Debería permitir la ejecución de cualquier comando que se pueda ejecutar desde la línea de comandos.
Se puede habilitar la validación del código de retorno y se puede especificar el código de retorno esperado.
Tenga en cuenta que los shells del sistema operativo generalmente proporcionan análisis de línea de comandos. Esto varía entre los sistemas operativos, pero generalmente el shell dividirá los parámetros en espacios en blanco. Algunos shells expanden los nombres de archivos comodín; algunos no. El mecanismo de cotización también varía entre los sistemas operativos. La muestra deliberadamente no realiza ningún análisis ni manejo de cotizaciones. El comando y sus parámetros deben proporcionarse en la forma esperada por el ejecutable. Esto significa que la configuración de la muestra no será transferible entre sistemas operativos.
Muchos sistemas operativos tienen algunos comandos integrados que no se proporcionan como ejecutables independientes. Por ejemplo, el comando DIR de Windows es parte del intérprete de comandos ( CMD.EXE ). Estos integrados no se pueden ejecutar como programas independientes, sino que se deben proporcionar como argumentos al intérprete de comandos adecuado.
Por ejemplo, la línea de comandos de Windows: DIR C:\TEMP debe especificarse de la siguiente manera:
- Dominio:
- CMD
- Parámetro 1:
- /C
- Parámetro 2:
- DIRECCIÓN
- Parámetro 3:
- C:\TEMP

Parámetros ¶
Secuencia de comandos MongoDB (DEPRECATED) ¶
Esta muestra le permite enviar una solicitud a un MongoDB.
Antes de usar esto, debe configurar un elemento de configuración de configuración de origen de MongoDB

Parámetros ¶
Solicitud de perno ¶
Esta muestra le permite ejecutar consultas Cypher a través del protocolo Bolt.
Antes de usar esto, debe configurar una configuración de conexión de pernos
Cada solicitud utiliza una conexión adquirida del grupo y la devuelve al grupo cuando se completa la muestra. El tamaño del grupo de conexiones usa los valores predeterminados del controlador (~100) y no se puede configurar en este momento.
El tiempo de respuesta medido corresponde a la ejecución de la consulta "completa", incluido el tiempo para ejecutar la consulta cifrada Y el tiempo para consumir los resultados enviados por la base de datos.

Parámetros ¶
18.2 Controladores lógicos ¶
Los controladores lógicos determinan el orden en que se procesan los muestreadores.
Controlador simple ¶
El controlador lógico simple le permite organizar sus muestreadores y otros controladores lógicos. A diferencia de otros Logic Controllers, este controlador no ofrece más funciones que las de un dispositivo de almacenamiento.

Parámetros ¶
Descargue este ejemplo (ver Figura 6). En este ejemplo, creamos un plan de prueba que envía dos solicitudes HTTP Ant y dos solicitudes HTTP Log4J. Agrupamos las solicitudes Ant y Log4J colocándolas dentro de Simple Logic Controllers. Recuerde, el controlador lógico simple no tiene ningún efecto sobre cómo JMeter procesa los controladores que le agrega. Entonces, en este ejemplo, JMeter envía las solicitudes en el siguiente orden: página de inicio de Ant, página de noticias de Ant, página de inicio de Log4J, página de historial de Log4J.
Tenga en cuenta que File Reporter está configurado para almacenar los resultados en un archivo llamado " simple-test.dat " en el directorio actual.

Controlador de bucle ¶
Si agrega controladores generativos o lógicos a un controlador de bucle, JMeter los recorrerá una cierta cantidad de veces, además del valor de bucle que especificó para el grupo de subprocesos. Por ejemplo, si agrega una solicitud HTTP a un controlador de bucle con un recuento de bucles de dos y configura el recuento de bucles del grupo de subprocesos en tres, JMeter enviará un total de 2 * 3 = 6 solicitudes HTTP.

Parámetros ¶
El valor -1 es equivalente a marcar la opción Siempre .
Caso especial: el controlador de bucle incrustado en el elemento Grupo de subprocesos se comporta de forma ligeramente diferente. A menos que se establezca para siempre, detiene la prueba después de que se haya realizado el número dado de iteraciones.
Descargue este ejemplo (ver Figura 4). En este ejemplo, creamos un plan de prueba que envía una solicitud HTTP particular solo una vez y envía otra solicitud HTTP cinco veces.

Configuramos el Grupo de subprocesos para un solo subproceso y un valor de recuento de bucles de uno. En lugar de dejar que Thread Group controle el bucle, usamos un controlador de bucle. Puede ver que agregamos una solicitud HTTP al grupo de subprocesos y otra solicitud HTTP a un controlador de bucle. Configuramos el controlador de bucle con un valor de conteo de bucle de cinco.
JMeter enviará las solicitudes en el siguiente orden: página de inicio, página de noticias, página de noticias, página de noticias, página de noticias y página de noticias.
Controlador de una sola vez ¶
El controlador lógico de una sola vez le dice a JMeter que procese los controladores dentro de él solo una vez por subproceso, y pase por alto cualquier solicitud debajo de él durante las iteraciones posteriores a través del plan de prueba.
El controlador de una sola vez ahora se ejecutará siempre durante la primera iteración de cualquier controlador principal en bucle. Por lo tanto, si el controlador de solo una vez se coloca bajo un controlador de bucle especificado para repetir 5 veces, entonces el controlador de solo una vez se ejecutará solo en la primera iteración a través del controlador de bucle (es decir, cada 5 veces).
Tenga en cuenta que esto significa que el controlador de una sola vez seguirá comportándose como se esperaba anteriormente si se coloca en un grupo de subprocesos (se ejecuta solo una vez por prueba por subproceso), pero ahora el usuario tiene más flexibilidad en el uso del controlador de una sola vez.
Para las pruebas que requieren un inicio de sesión, considere colocar la solicitud de inicio de sesión en este controlador, ya que cada subproceso solo necesita iniciar sesión una vez para establecer una sesión.

Parámetros ¶
Descargue este ejemplo (ver Figura 5). En este ejemplo, creamos un plan de prueba que tiene dos subprocesos que envían una solicitud HTTP. Cada subproceso envía una solicitud a la página de inicio, seguida de tres solicitudes a la página de error. Aunque configuramos el grupo de subprocesos para iterar tres veces, cada subproceso de JMeter solo envía una solicitud a la página de inicio porque esta solicitud vive dentro de un controlador de una sola vez.

Cada subproceso de JMeter enviará las solicitudes en el siguiente orden: página de inicio, página de error, página de error, página de error.
Tenga en cuenta que File Reporter está configurado para almacenar los resultados en un archivo llamado " loop-test.dat " en el directorio actual.
Controlador intercalado ¶
Si agrega controladores generativos o lógicos a un controlador intercalado, JMeter alternará entre cada uno de los otros controladores para cada iteración de bucle.

Parámetros ¶
Descargue este ejemplo (ver Figura 1). En este ejemplo, configuramos el Grupo de subprocesos para que tenga dos subprocesos y un número de bucles de cinco, para un total de diez solicitudes por subproceso. Consulte la siguiente tabla para conocer la secuencia en que JMeter envía las solicitudes HTTP.

| Iteración de bucle | Cada subproceso de JMeter envía estas solicitudes HTTP |
|---|---|
| 1 | Página de noticias |
| 1 | Página de registro |
| 2 | Página de preguntas frecuentes |
| 2 | Página de registro |
| 3 | Página de Gump |
| 3 | Página de registro |
| 4 | Debido a que no hay más solicitudes en el controlador, JMeter comienza de nuevo y envía la primera solicitud HTTP, que es la página de noticias. |
| 4 | Página de registro |
| 5 | Página de preguntas frecuentes |
| 5 | Página de registro |
Descargue otro ejemplo (ver Figura 2). En este ejemplo, configuramos el Grupo de subprocesos para tener un solo subproceso y un número de bucles de ocho. Observe que el plan de prueba tiene un controlador intercalado externo con dos controladores intercalados dentro.

El Interleave Controller externo alterna entre los dos internos. Luego, cada Interleave Controller interno alterna entre cada una de las solicitudes HTTP. Cada subproceso de JMeter enviará las solicitudes en el siguiente orden: página de inicio, intercalado, página de error, intercalado, página de CVS, intercalado y página de preguntas frecuentes, intercalado.
Tenga en cuenta que File Reporter está configurado para almacenar los resultados en un archivo llamado " interleave-test2.dat " en el directorio actual.

Si los dos controladores intercalados debajo del controlador intercalado principal fueran controladores simples, entonces el orden sería: Página de inicio, Página CVS, Intercalado, Página de errores, Página de preguntas frecuentes, Intercalado.
Sin embargo, si se marcó " ignorar los bloques del subcontrolador " en el controlador intercalado principal, entonces el orden sería: página de inicio, intercalado, página de errores, intercalado, página CVS, intercalado y página de preguntas frecuentes, intercalado.
Controlador aleatorio ¶
El Controlador Lógico Aleatorio actúa de manera similar al Controlador Intercalado, excepto que en lugar de ir en orden a través de sus subcontroladores y muestreadores, elige uno al azar en cada pasada.

Parámetros ¶
Controlador de orden aleatorio ¶
El controlador de orden aleatorio se parece mucho a un controlador simple en el sentido de que ejecutará cada elemento secundario como máximo una vez, pero el orden de ejecución de los nodos será aleatorio.

Parámetros ¶
Controlador de rendimiento ¶
El controlador de rendimiento permite al usuario controlar la frecuencia con la que se ejecuta. Hay dos modos:
- porcentaje de ejecución
- ejecuciones totales
- Porcentaje de ejecuciones
- hace que el controlador ejecute un cierto porcentaje de las iteraciones a través del plan de prueba.
- Ejecuciones totales
- hace que el controlador deje de ejecutarse después de que haya ocurrido un cierto número de ejecuciones.

Parámetros ¶
Controlador de tiempo de ejecución ¶
El controlador de tiempo de ejecución controla cuánto tiempo se ejecutarán sus hijos. El controlador ejecutará a sus hijos hasta que se excedan los tiempos de ejecución configurados.

Parámetros ¶
Si controlador ¶
El controlador If permite al usuario controlar si los elementos de prueba debajo de él (sus hijos) se ejecutan o no.
De forma predeterminada, la condición se evalúa solo una vez en la entrada inicial, pero tiene la opción de evaluarla para cada elemento ejecutable contenido en el controlador.
La mejor opción (la predeterminada) es marcar ¿Interpretar condición como expresión variable? , luego en el campo de condición tienes 2 opciones:
- Opción 1: Usar una variable que contenga verdadero o falso
Si desea probar si la última muestra fue exitosa, puede usar ${JMeterThread.last_sample_ok}
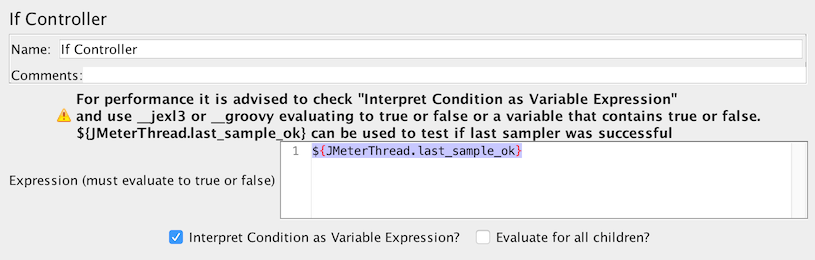
Si el controlador usa variable - Opción 2: use una función ( se recomienda ${__jexl3()} ) para evaluar una expresión que debe devolver verdadero o falso
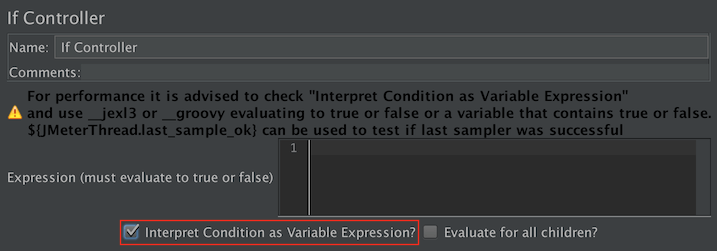
Si el controlador usa la expresión

"${miVar}" == "\${miVar}"
O usar:
"${miVar}" != "\${miVar}"
para probar si una variable está definida y no es nula.


Parámetros ¶
- ${CONTADOR} < 10
- "${VAR}" == "abcd"
Cuando use __groovy , tenga cuidado de no usar el reemplazo de variables en la cadena, de lo contrario, si usa una variable que cambia, la secuencia de comandos no se puede almacenar en caché. En su lugar, obtenga la variable usando: vars.get("myVar"). Vea los ejemplos de Groovy a continuación.
- ${__groovy(vars.get("myVar") != "Invalid" )} (Groovy check myVar no es igual a Invalid)
- ${__groovy(vars.get("myInt").toInteger() <=4 )} (Groovy check myInt es menor o igual a 4)
- ${__groovy(vars.get("myMissing") != null )} (Groovy verifique si la variable myMissing no está configurada)
- ${__jexl3(${CONTAR} < 10)}
- ${RESULTADO}
- ${JMeterThread.last_sample_ok} (verifique si la última muestra tuvo éxito)
Mientras que controlador ¶
El controlador while ejecuta a sus hijos hasta que la condición es " falsa ".
Posibles valores de condición:
- en blanco: sale del ciclo cuando falla la última muestra en el ciclo
- LAST : sale del bucle cuando falla la última muestra del bucle. Si la última muestra justo antes del ciclo falló, no ingrese el ciclo.
- De lo contrario, salga (o no ingrese) del bucle cuando la condición sea igual a la cadena " falso "
Por ejemplo:
- ${VAR} - donde VAR se establece en falso por algún otro elemento de prueba
- ${__jexl3(${C}==10)}
- ${__jexl3("${VAR2}"=="abcd")}
- ${_P(propiedad)} - donde la propiedad se establece en " falso " en otro lugar

Parámetros ¶
Controlador de interruptores ¶
El Switch Controller actúa como el Interleave Controller en el sentido de que ejecuta uno de los elementos subordinados en cada iteración, pero en lugar de ejecutarlos en secuencia, el controlador ejecuta el elemento definido por el valor del switch.
Si el valor del interruptor está fuera de rango, ejecutará el elemento cero, que por lo tanto actúa como valor predeterminado para el caso numérico. También ejecuta el elemento cero si el valor es la cadena vacía.
Si el valor no es numérico (y no está vacío), Switch Controller busca el elemento con el mismo nombre (las mayúsculas y minúsculas son significativas). Si ninguno de los nombres coincide, se selecciona el elemento denominado " predeterminado " (mayúsculas y minúsculas no significativas). Si no hay un valor predeterminado, entonces no se selecciona ningún elemento y el controlador no ejecutará nada.

Parámetros ¶
Para cada controlador ¶
Un controlador ForEach recorre los valores de un conjunto de variables relacionadas. Cuando agrega muestras (o controladores) a un controlador ForEach, cada muestra (o controlador) se ejecuta una o más veces, donde durante cada ciclo la variable tiene un nuevo valor. La entrada debe constar de varias variables, cada una extendida con un guión bajo y un número. Cada una de estas variables debe tener un valor. Entonces, por ejemplo, cuando la variable de entrada tiene el nombre inputVar , se deberían haber definido las siguientes variables:
- entradaVar_1 = Wendy
- inputVar_2 = charles
- inputVar_3 = pedro
- inputVar_4 = juan
Nota: el separador " _ " ahora es opcional.
Cuando la variable de retorno se proporciona como " returnVar ", la colección de muestreadores y controladores bajo el controlador ForEach se ejecutará 4 veces consecutivas, y la variable de retorno tendrá los valores anteriores respectivos, que luego se pueden usar en los muestreadores.
Es especialmente adecuado para ejecutarse con el posprocesador de expresiones regulares. Esto puede "crear" las variables de entrada necesarias a partir de los datos de resultado de una solicitud anterior. Al omitir el separador " _ ", el controlador ForEach se puede usar para recorrer los grupos usando la variable de entrada refName_g , y también puede recorrer todos los grupos en todas las coincidencias usando una variable de entrada de la forma refName_${C }_g , donde C es una variable de contador.

Parámetros ¶
Descargue este ejemplo (ver Figura 7). En este ejemplo, creamos un plan de prueba que envía una solicitud HTTP particular solo una vez y envía otra solicitud HTTP a cada enlace que se puede encontrar en la página.

Configuramos el Grupo de subprocesos para un solo subproceso y un valor de recuento de bucles de uno. Puede ver que agregamos una solicitud HTTP al grupo de subprocesos y otra solicitud HTTP al controlador ForEach.
Después de la primera solicitud HTTP, se agrega un extractor de expresiones regulares, que extrae todos los enlaces html de la página de retorno y los coloca en la variable inputVar.
En el bucle ForEach, se agrega una muestra HTTP que solicita todos los enlaces que se extrajeron de la primera página HTML devuelta.
Aquí hay otro ejemplo que puede descargar. Esto tiene dos expresiones regulares y controladores ForEach. El primer RE coincide, pero el segundo no, por lo que el segundo controlador ForEach no ejecuta muestras.

El grupo de subprocesos tiene un solo subproceso y un número de bucles de dos.
El ejemplo 1 utiliza JavaTest Sampler para devolver la cadena " abcd ".
Regex Extractor usa la expresión (\w)\s que coincide con una letra seguida de un espacio y devuelve la letra (no el espacio). Cualquier coincidencia tiene como prefijo la cadena " inputVar ".
El controlador ForEach extrae todas las variables con el prefijo " inputVar_ " y ejecuta su muestra, pasando el valor en la variable " returnVar ". En este caso establecerá la variable a los valores " a " " b " y " c " a su vez.
For 1 Sampler es otro Java Sampler que utiliza la variable de retorno " returnVar " como parte de la etiqueta de muestra y como datos de muestra.
Sample 2 , Regex 2 y For 2 son casi idénticos, excepto que Regex se ha cambiado a " (\w)\sx ", que claramente no coincidirá. Por lo tanto , For 2 Sampler no se ejecutará.
Controlador de módulo ¶
El controlador del módulo proporciona un mecanismo para sustituir fragmentos del plan de prueba en el plan de prueba actual en tiempo de ejecución.
Un fragmento de plan de prueba consta de un controlador y todos los elementos de prueba (muestras, etc.) que contiene. El fragmento se puede ubicar en cualquier grupo de subprocesos. Si el fragmento está ubicado en un grupo de subprocesos, su controlador se puede desactivar para evitar que el fragmento se ejecute excepto por el controlador del módulo. O puede almacenar los fragmentos en un grupo de subprocesos ficticio y deshabilitar todo el grupo de subprocesos.
Puede haber múltiples fragmentos, cada uno con una serie diferente de muestras debajo de ellos. El controlador del módulo se puede usar para cambiar fácilmente entre estos múltiples casos de prueba simplemente eligiendo el controlador apropiado en su cuadro desplegable. Esto proporciona comodidad para ejecutar muchos planes de prueba alternativos de forma rápida y sencilla.
Un nombre de fragmento se compone del nombre del controlador y todos sus nombres principales. Por ejemplo:
Plan de prueba/Protocolo: JDBC/Control/Controlador intercalado (Módulo 1)
Cualquier fragmento utilizado por el controlador del módulo debe tener un nombre único , ya que el nombre se utiliza para encontrar el controlador de destino cuando se vuelve a cargar un plan de prueba. Por esta razón, es mejor asegurarse de que el nombre del controlador se cambie del predeterminado, como se muestra en el ejemplo anterior; de lo contrario, se puede crear un duplicado accidentalmente cuando se agregan nuevos elementos al plan de prueba.

Parámetros ¶
Incluir controlador ¶
El controlador de inclusión está diseñado para utilizar un archivo JMX externo. Para usarlo, cree un Fragmento de prueba debajo del Plan de prueba y agregue los muestreadores, controladores, etc. que desee debajo. Luego guarde el plan de prueba. El archivo ahora está listo para incluirse como parte de otros planes de prueba.
Para mayor comodidad, también se puede agregar un grupo de subprocesos en el archivo JMX externo para fines de depuración. Se puede utilizar un controlador de módulo para hacer referencia al fragmento de prueba. El grupo de subprocesos se ignorará durante el proceso de inclusión.
Si la prueba utiliza un administrador de cookies o variables definidas por el usuario, estas deben colocarse en el plan de prueba de nivel superior, no en el archivo incluido; de lo contrario, no se garantiza que funcionen.
Sin embargo, si se define la propiedad includecontroller.prefix , el contenido se utiliza como prefijo de la ruta.
Si el archivo no se puede encontrar en la ubicación proporcionada por prefijo + nombre de archivo , el controlador intenta abrir el nombre de archivo relativo al directorio de inicio de JMX.

Controlador de transacciones ¶
Transaction Controller genera una muestra adicional que mide el tiempo total necesario para realizar los elementos de prueba anidados.
Hay dos modos de funcionamiento:
- se agrega una muestra adicional después de las muestras anidadas
- se agrega una muestra adicional como padre de las muestras anidadas
El tiempo de muestra generado incluye todos los tiempos para los muestreadores anidados, excluyendo de forma predeterminada (desde 2.11) los temporizadores y el tiempo de procesamiento de los pre/postprocesadores, a menos que se marque la casilla de verificación " Incluir la duración del cronómetro y los pre-postprocesadores en la muestra generada ". Dependiendo de la resolución del reloj, puede ser un poco más largo que la suma de los muestreadores individuales más los temporizadores. El reloj puede funcionar después de que el controlador registró la hora de inicio, pero antes de que comience la primera muestra. Del mismo modo al final.
La muestra generada solo se considera correcta si todas sus submuestras lo son.
En el modo principal, las muestras individuales todavía se pueden ver en el Oyente de vista de árbol, pero ya no aparecen como entradas separadas en otros Oyentes. Además, las submuestras no aparecen en los archivos de registro CSV, pero se pueden guardar en archivos XML.

Parámetros ¶
Controlador de grabación ¶
El controlador de grabación es un marcador de posición que indica dónde debe grabar las muestras el servidor proxy. Durante la ejecución de prueba, no tiene ningún efecto, similar al controlador simple. Sin embargo, durante la grabación con HTTP(S) Test Script Recorder , todas las muestras grabadas se guardarán de forma predeterminada en el controlador de grabación.

Parámetros ¶
Controlador de Sección Crítica ¶
El controlador de sección crítica garantiza que sus elementos secundarios (muestreadores/controladores, etc.) serán ejecutados por un solo subproceso, ya que se tomará un bloqueo con nombre antes de ejecutar los elementos secundarios del controlador.

La figura a continuación muestra un ejemplo del uso del controlador de sección crítica, en la figura a continuación, 2 controladores de sección crítica aseguran que:
- DS2-${__threadNum} es ejecutado solo por un subproceso a la vez
- DS4-${__threadNum} solo lo ejecuta un subproceso a la vez

Parámetros ¶
18.3 Oyentes ¶
La mayoría de los oyentes realizan varias funciones además de "escuchar" los resultados de las pruebas. También proporcionan medios para ver, guardar y leer los resultados de las pruebas guardadas.
Tenga en cuenta que los oyentes se procesan al final del ámbito en el que se encuentran.
El guardado y lectura de los resultados de las pruebas es genérico. Los diversos oyentes tienen un panel en el que se puede especificar el archivo en el que se escribirán (o leerán) los resultados. De forma predeterminada, los resultados se almacenan como archivos XML, normalmente con una extensión " .jtl ". Almacenar como CSV es la opción más eficiente, pero es menos detallada que XML (la otra opción disponible).
Los oyentes no procesan datos de muestra en el modo CLI, pero los datos sin procesar se guardarán si se ha configurado un archivo de salida. Para analizar los datos generados por una ejecución de CLI, debe cargar el archivo en el Listener apropiado.
Si desea borrar los datos actuales antes de cargar un nuevo archivo, use el elemento de menú o antes de cargar el archivo.
Los resultados se pueden leer desde archivos en formato XML o CSV. Al leer archivos de resultados CSV, el encabezado (si está presente) se usa para determinar qué campos están presentes. Para interpretar correctamente un archivo CSV sin encabezado, se deben establecer las propiedades apropiadas en jmeter.properties .
Los oyentes pueden usar mucha memoria si hay muchas muestras. La mayoría de los oyentes actualmente guardan una copia de cada muestra en su alcance, además de:
- Escritor de datos simple
- Oyente BeanShell/JSR223
- Visualizador de correo
- Informe resumido
Los siguientes oyentes ya no necesitan guardar copias de cada muestra. En su lugar, se agregan las muestras con el mismo tiempo transcurrido. Ahora se necesita menos memoria, especialmente si la mayoría de las muestras solo toman uno o dos segundos como máximo.
- Informe agregado
- Gráfico agregado
Para minimizar la cantidad de memoria necesaria, use Simple Data Writer y use el formato CSV.
Para obtener detalles completos sobre la configuración de los elementos predeterminados que se guardarán, consulte la documentación de Configuración predeterminada del oyente . Para obtener detalles sobre el contenido de los archivos de salida, consulte el formato de registro CSV o el formato de registro XML .
La siguiente figura muestra un ejemplo del panel de configuración del archivo de resultados

Parámetros
Ejemplo de configuración para guardar resultados ¶
Los oyentes se pueden configurar para guardar diferentes elementos en los archivos de registro de resultados (JTL) utilizando la ventana emergente de configuración como se muestra a continuación. Los valores predeterminados se definen como se describe en la documentación de configuración predeterminada de escucha . Los elementos con ( CSV ) después del nombre solo se aplican al formato CSV; los elementos con ( XML ) solo se aplican al formato XML. Actualmente, el formato CSV no se puede utilizar para guardar elementos que incluyan saltos de línea.
Tenga en cuenta que las cookies, el método y la cadena de consulta se guardan como parte de la opción " Datos de muestra".

Resultados del gráfico ¶
El oyente Graph Results genera un gráfico simple que traza todos los tiempos de muestra. En la parte inferior del gráfico, la muestra actual (negro), el promedio actual de todas las muestras (azul), la desviación estándar actual (rojo) y la tasa de rendimiento actual (verde) se muestran en milisegundos.
El número de rendimiento representa el número real de solicitudes por minuto que manejó el servidor. Este cálculo incluye cualquier retraso que haya agregado a su prueba y el propio tiempo de procesamiento interno de JMeter. La ventaja de hacer el cálculo de esta manera es que este número representa algo real: su servidor, de hecho, manejó esa cantidad de solicitudes por minuto, y puede aumentar la cantidad de subprocesos y/o disminuir las demoras para descubrir el rendimiento máximo de su servidor. Mientras que si realizó cálculos que excluyeron los retrasos y el procesamiento de JMeter, no estaría claro qué podría concluir a partir de ese número.

La siguiente tabla describe brevemente los elementos del gráfico. Se pueden encontrar más detalles sobre el significado preciso de los términos estadísticos en la web, por ejemplo, Wikipedia, o consultando un libro sobre estadísticas.
- Datos : trace los valores de datos reales
- Promedio - trace el Promedio
- Mediana : trace la mediana (valor medio)
- Desviación : trace la desviación estándar (una medida de la variación)
- Rendimiento : represente el número de muestras por unidad de tiempo
Las cifras individuales en la parte inferior de la pantalla son los valores actuales. " Última muestra " es el tiempo de muestra actual transcurrido, que se muestra en el gráfico como " Datos ".
El valor que se muestra en la parte superior izquierda del gráfico es el máximo del percentil 90 del tiempo de respuesta.
Resultados de la afirmación ¶
El visualizador de resultados de aserción muestra la etiqueta de cada muestra tomada. También informa fallas de cualquier aserción que sea parte del plan de prueba.

Ver árbol de resultados ¶
Hay varias formas de ver la respuesta, que se pueden seleccionar mediante un cuadro desplegable en la parte inferior del panel izquierdo.
| renderizador | Descripción |
|---|---|
| Probador de CSS/JQuery | El CSS/JQuery Tester solo funciona para respuestas de texto. Muestra el texto sin formato en el panel superior. El botón " Probar " permite al usuario aplicar el CSS/JQuery al panel superior y los resultados se mostrarán en el panel inferior. El motor de expresión CSS/JQuery puede ser JSoup o Jodd, la sintaxis de estas 2 implementaciones difiere ligeramente. Por ejemplo, el Selector a[class=sectionlink] con el atributo href aplicado a la página de funciones de JMeter actual da el siguiente resultado: Recuento de coincidencias: 74 Coincidencia[1]=#funciones Partido[2]=#qué_puede_hacer Partido[3]=#dónde Partido[4]=#cómo Partido[5]=#función_ayudante Coincidencia[6]=#funciones Coincidencia[7]=#__regexFunción Coincidencia[8]=#__regexFunction_parms Partido[9]=#__contador … y así … |
| Documento | La vista Documento mostrará el texto extraído de varios tipos de documentos como Microsoft Office (Word, Excel, PowerPoint 97-2003, 2007-2010 (openxml), Apache OpenOffice (writer, calc, impress), HTML, gzip, jar/zip archivos (lista de contenido) y algunos metadatos en archivos "multimedia" como mp3, mp4, flv, etc. La lista completa de formatos compatibles está disponible en la página de formato Apache Tika.
Un requisito para la vista Documento es descargar el
paquete binario de Apache Tika ( tika-app-xxjar ) y colocarlo en el directorio JMETER_HOME/lib .
Si el documento tiene más de 10 MB, no se mostrará. Para cambiar este límite, establezca la propiedad de JMeter document.max_size (la unidad es un byte) o establezca en 0 para eliminar el límite.
|
| HTML | La vista HTML intenta representar la respuesta como HTML. Es probable que el HTML renderizado se compare mal con la vista que se obtendría en cualquier navegador web; sin embargo, proporciona una aproximación rápida que es útil para la evaluación inicial de resultados. No se descargan imágenes, hojas de estilo, etc. |
| HTML (descargar recursos) | Si se selecciona la opción de vista HTML (descargar recursos) , el renderizador puede descargar imágenes, hojas de estilo, etc. a las que hace referencia el código HTML.
|
| Fuente HTML formateada | Si se selecciona la opción de vista con formato fuente HTML , el renderizador mostrará el código fuente HTML formateado y limpiado por Jsoup .
|
| JSON | La vista JSON mostrará la respuesta en estilo de árbol (también maneja JSON incrustado en JavaScript).
|
| Probador de rutas JSON | La vista JSON Path Tester le permitirá probar sus expresiones JSON-PATH y ver los datos extraídos de una respuesta en particular.
|
| JSON JMESPath Tester | La vista JSON JMESPath Tester le permitirá probar sus expresiones JMESPath y ver los datos extraídos de una respuesta particular.
|
| Probador de expresiones regulares | La vista Regexp Tester solo funciona para respuestas de texto. Muestra el texto sin formato en el panel superior. El botón " Probar " permite al usuario aplicar la expresión regular al panel superior y los resultados se mostrarán en el panel inferior. El motor de expresiones regulares es el mismo que se usa en el Extractor de expresiones regulares. Por ejemplo, el RE (JMeter\w*).* aplicado a la página de inicio de JMeter actual da el siguiente resultado: Número de partidos: 26 Partido[1][0]=JMeter - Apache JMeter</título> Partido[1][1]=JMeter Coincidencia[2][0]=JMeter" title="JMeter" border="0"/></a> Partido[2][1]=JMetro Match[3][0]=JMeterCommitters">Contribuidores</a> Partido[3][1]=JMeterCommitters … y así … El primer número entre [] es el número de coincidencia; el segundo número es el grupo. El grupo [0] es lo que coincida con todo el RE. El grupo [1] es lo que coincida con el primer grupo, es decir, (JMeter\w*) en este caso. Consulte la Figura 9b (a continuación). |
| Texto | La vista Texto
predeterminada muestra todo el texto contenido en la respuesta. Tenga en cuenta que esto solo funcionará si el tipo de contenido de la respuesta se considera texto. Si el tipo de contenido comienza con cualquiera de los siguientes, se considera binario; de lo contrario, se considera texto.
imagen/ audio/ video/ |
| XML | La vista XML mostrará la respuesta en estilo de árbol. Cualquier nodo DTD o nodo Prolog no aparecerá en el árbol; sin embargo, la respuesta puede contener esos nodos. Puede hacer clic con el botón derecho en cualquier nodo y expandir o contraer todos los nodos debajo de él.
|
| Probador de XPath | XPath Tester solo funciona para respuestas de texto. Muestra el texto sin formato en el panel superior. El botón " Probar " permite al usuario aplicar la consulta XPath al panel superior y los resultados se mostrarán en el panel inferior. |
| Probador de extractor de límites | El Boundary Extractor Tester solo funciona para respuestas de texto. Muestra el texto sin formato en el panel superior. El botón " Probar " permite al usuario aplicar la consulta del extractor de límites al panel superior y los resultados se mostrarán en el panel inferior. |
Desplazarse automáticamente? opción de permiso para mostrar el último nodo en la selección de árbol
Con la opción Buscar , la mayoría de las vistas también permiten buscar los datos mostrados; el resultado de la búsqueda se resaltará en la pantalla de arriba. Por ejemplo, la siguiente captura de pantalla del panel de control muestra un resultado de la búsqueda de " Java ". Tenga en cuenta que la búsqueda opera en el texto visible, por lo que puede obtener resultados diferentes al buscar en las vistas Texto y HTML.
Nota: La expresión regular utiliza el motor Java (no el motor ORO como la vista Regular Expression Extractor o Regexp Tester).
Si no se proporciona ningún tipo de contenido , el contenido no se mostrará en ninguno de los paneles de Datos de respuesta. Puede usar Guardar respuestas en un archivo para guardar los datos en este caso. Tenga en cuenta que los datos de respuesta seguirán estando disponibles en el resultado de la muestra, por lo que aún se puede acceder a ellos mediante posprocesadores.
Si los datos de respuesta superan los 200 000, no se mostrarán. Para cambiar este límite, establezca la propiedad de JMeter view.results.tree.max_size . También puede guardar la respuesta completa en un archivo usando Guardar respuestas en un archivo .
Se pueden crear renderizadores adicionales. La clase debe implementar la interfaz org.apache.jmeter.visualizers.ResultRenderer y/o extender la clase abstracta org.apache.jmeter.visualizers.SamplerResultTab , y el código compilado debe estar disponible para JMeter (por ejemplo, agregándolo a lib/ directorio externo ).

El Panel de control (arriba) muestra un ejemplo de una pantalla HTML.
La Figura 9 (abajo) muestra un ejemplo de una pantalla XML.
La Figura 9a (abajo) muestra un ejemplo de una pantalla de probador Regexp.
La Figura 9b (abajo) muestra un ejemplo de una pantalla de Documento.



Informe agregado ¶
El rendimiento se calcula desde el punto de vista del objetivo del muestreador (por ejemplo, el servidor remoto en el caso de muestras HTTP). JMeter tiene en cuenta el tiempo total durante el cual se han generado las solicitudes. Si hay otros muestreadores y temporizadores en el mismo subproceso, aumentarán el tiempo total y, por lo tanto, reducirán el valor de rendimiento. Por lo tanto, dos muestreadores idénticos con nombres diferentes tendrán la mitad del rendimiento de dos muestreadores con el mismo nombre. Es importante elegir correctamente los nombres de las muestras para obtener los mejores resultados del informe agregado.
El cálculo de los valores de la mediana y la línea del 90 % (percentil 90 ) requiere memoria adicional. JMeter ahora combina muestras con el mismo tiempo transcurrido, por lo que se utiliza mucha menos memoria. Sin embargo, para las muestras que toman más de unos pocos segundos, la probabilidad es que menos muestras tengan tiempos idénticos, en cuyo caso se necesitará más memoria. Tenga en cuenta que puede usar este oyente después para volver a cargar un archivo de resultados CSV o XML, que es la forma recomendada de evitar impactos en el rendimiento. Consulte el Informe resumido para ver un Listener similar que no almacena muestras individuales y, por lo tanto, necesita una memoria constante.
- Etiqueta - La etiqueta de la muestra. Si se selecciona "¿ Incluir el nombre del grupo en la etiqueta? ", el nombre del grupo de subprocesos se agrega como prefijo. Esto permite clasificar etiquetas idénticas de diferentes grupos de hilos por separado si es necesario.
- # Samples - El número de muestras con la misma etiqueta
- Promedio : el tiempo promedio de un conjunto de resultados
- Mediana : la mediana es el tiempo en medio de un conjunto de resultados. El 50 % de las muestras no tomó más de este tiempo; el resto tomó al menos el mismo tiempo.
- Línea del 90 %: el 90 % de las muestras no tomó más de este tiempo. Las muestras restantes tomaron al menos tanto tiempo como este. ( percentil 90 )
- Línea del 95 %: el 95 % de las muestras no tomó más de este tiempo. Las muestras restantes tardaron al menos tanto como esto. ( percentil 95 )
- Línea del 99 %: el 99 % de las muestras no tomó más de este tiempo. Las muestras restantes tardaron al menos tanto como esto. ( percentil 99 )
- Min - El tiempo más corto para las muestras con la misma etiqueta
- Max: el tiempo más largo para las muestras con la misma etiqueta
- Error % - Porcentaje de solicitudes con errores
- Rendimiento : el rendimiento se mide en solicitudes por segundo/minuto/hora. La unidad de tiempo se elige de modo que la tasa mostrada sea al menos 1,0. Cuando el rendimiento se guarda en un archivo CSV, se expresa en solicitudes/segundo, es decir, 30,0 solicitudes/minuto se guardan como 0,5.
- KB/s recibidos : el rendimiento medido en kilobytes recibidos por segundo
- KB/s enviados : el rendimiento medido en kilobytes enviados por segundo
Los tiempos están en milisegundos.

La siguiente figura muestra un ejemplo de selección de la casilla de verificación " Incluir nombre de grupo ".

Ver resultados en tabla ¶
De forma predeterminada, solo muestra las muestras principales (principales); no muestra las submuestras (muestras secundarias). JMeter tiene una casilla de verificación " ¿Muestras secundarias? ". Si se selecciona, se muestran las submuestras en lugar de las muestras principales.

Escritor de datos simple ¶
Gráfico agregado ¶

La siguiente figura muestra un ejemplo de configuración para dibujar este gráfico.

Parámetros ¶
- Columnas para mostrar: Elija la(s) columna(s) para mostrar en el gráfico.
- Color de los rectángulos: haga clic en el rectángulo de color derecho para abrir un cuadro de diálogo emergente para elegir un color personalizado para la columna.
- Color de primer plano Permite cambiar el color del texto del valor.
- Fuente de valor: permite definir la configuración de fuente para el texto.
- ¿Dibujar barra de contornos? Para dibujar o no la línea de borde en el gráfico de barras
- ¿Mostrar agrupación de números? Mostrar o no la agrupación de números en las etiquetas del eje Y.
- ¿Etiquetas de valor verticales? Cambiar la orientación de la etiqueta de valor. (El valor predeterminado es horizontal)
-
Selección de etiqueta de columna: filtrar por etiqueta de resultado. Se puede usar una expresión regular, por ejemplo: .*Transacción.*
Antes de mostrar el gráfico, haga clic en el botón Aplicar filtro para actualizar los datos internos.
Gráfico de tiempo de respuesta ¶

La siguiente figura muestra un ejemplo de configuración para dibujar este gráfico.

Parámetros ¶
Visualizador de correo ¶
El visualizador de correo se puede configurar para enviar correo electrónico si una ejecución de prueba recibe demasiadas respuestas fallidas del servidor.

Parámetros ¶
Oyente BeanShell ¶
BeanShell Listener permite el uso de BeanShell para procesar muestras para guardar, etc.
Para obtener detalles completos sobre el uso de BeanShell, consulte el sitio web de BeanShell.
El elemento de prueba admite los métodos ThreadListener y TestListener . Estos deben definirse en el archivo de inicialización. Consulte el archivo BeanShellListeners.bshrc para ver definiciones de ejemplo.

Parámetros ¶
- Parámetros
- cadena que contiene los parámetros como una sola variable
- bsh.args
- Matriz de cadenas que contiene parámetros, dividida en espacios en blanco
Antes de invocar el script, se configuran algunas variables en el intérprete BeanShell:
- log - ( Registrador ) - se puede usar para escribir en el archivo de registro
- ctx - ( JMeterContext ) - da acceso al contexto
-
vars - ( JMeterVariables ) - otorga acceso de lectura/escritura a las variables:
vars.get(clave); vars.put(clave,valor); vars.putObject("OBJ1",nuevo Objeto()); - props - (JMeterProperties - clase java.util.Properties ) - por ejemplo, props.get("START.HMS"); props.put("PROP1","1234");
- sampleResult , prev - ( SampleResult ) - da acceso al SampleResult anterior
- sampleEvent ( SampleEvent ) da acceso al evento de muestra actual
Para obtener detalles de todos los métodos disponibles en cada una de las variables anteriores, consulte el Javadoc
Si se define la propiedad beanshell.listener.init , se usa para cargar un archivo de inicialización, que se puede usar para definir métodos, etc. para usar en el script BeanShell.
Informe resumido ¶
El rendimiento se calcula desde el punto de vista del objetivo del muestreador (por ejemplo, el servidor remoto en el caso de muestras HTTP). JMeter tiene en cuenta el tiempo total durante el cual se han generado las solicitudes. Si hay otros muestreadores y temporizadores en el mismo subproceso, aumentarán el tiempo total y, por lo tanto, reducirán el valor de rendimiento. Por lo tanto, dos muestreadores idénticos con nombres diferentes tendrán la mitad del rendimiento de dos muestreadores con el mismo nombre. Es importante elegir correctamente las etiquetas de muestra para obtener los mejores resultados del Informe.
- Etiqueta - La etiqueta de la muestra. Si se selecciona "¿ Incluir el nombre del grupo en la etiqueta? ", el nombre del grupo de subprocesos se agrega como prefijo. Esto permite clasificar etiquetas idénticas de diferentes grupos de hilos por separado si es necesario.
- # Samples - El número de muestras con la misma etiqueta
- Promedio : el tiempo promedio transcurrido de un conjunto de resultados
- Min : el tiempo transcurrido más bajo para las muestras con la misma etiqueta
- Max : el tiempo transcurrido más largo para las muestras con la misma etiqueta
- estándar desarrollo - la desviación estándar del tiempo transcurrido de la muestra
- Error % - Porcentaje de solicitudes con errores
- Rendimiento : el rendimiento se mide en solicitudes por segundo/minuto/hora. La unidad de tiempo se elige de modo que la tasa mostrada sea al menos 1.0 . Cuando el rendimiento se guarda en un archivo CSV, se expresa en solicitudes/segundo, es decir, 30,0 solicitudes/minuto se guardan como 0,5 .
- KB/s recibidos : el rendimiento medido en kilobytes por segundo
- KB/s enviados : el rendimiento medido en kilobytes por segundo
- Promedio Bytes : tamaño promedio de la respuesta de la muestra en bytes.
Los tiempos están en milisegundos.

La siguiente figura muestra un ejemplo de selección de la casilla de verificación " Incluir nombre de grupo ".

Guardar respuestas en un archivo ¶
Este elemento de prueba se puede colocar en cualquier parte del plan de prueba. Para cada muestra en su ámbito, creará un archivo de los Datos de respuesta. El uso principal para esto es en la creación de pruebas funcionales, pero también puede ser útil cuando la respuesta es demasiado grande para mostrarse en Ver resultados del árbol de escucha. El nombre del archivo se crea a partir del prefijo especificado, más un número (a menos que esté deshabilitado, consulte a continuación). La extensión del archivo se crea a partir del tipo de documento, si se conoce. Si no se conoce, la extensión del archivo se establece en ' desconocido'. Si la numeración está deshabilitada y la adición de un sufijo está deshabilitada, el prefijo del archivo se toma como el nombre completo del archivo. Esto permite generar un nombre de archivo fijo si es necesario. El nombre del archivo generado se almacena en la respuesta de muestra y se puede guardar en el archivo de salida del registro de prueba si es necesario.
La muestra actual se guarda primero, seguida de cualquier submuestra (muestras secundarias). Si se proporciona un nombre de variable, los nombres de los archivos se guardan en el orden en que aparecen las submuestras. Vea abajo.

Parámetros ¶
Si las carpetas principales en el prefijo no existen, JMeter las creará y detendrá la prueba si falla.
Oyente JSR223 ¶
El JSR223 Listener permite que el código de script JSR223 se aplique a los resultados de la muestra.
Parámetros ¶
- Parámetros
- cadena que contiene los parámetros como una sola variable
- argumentos
- Matriz de cadenas que contiene parámetros, dividida en espacios en blanco
Antes de invocar el script, se configuran algunas variables. Tenga en cuenta que estas son variables JSR223, es decir, se pueden usar directamente en el script.
- Iniciar sesión
- ( Registrador ): se puede usar para escribir en el archivo de registro
- Etiqueta
- la etiqueta de cadena
- Nombre del archivo
- el nombre del archivo de script (si lo hay)
- Parámetros
- los parámetros (como una cadena)
- argumentos
- los parámetros como una matriz de cadenas (dividida en espacios en blanco)
- ctx
- ( JMeterContext ) - da acceso al contexto
- vars
- ( JMeterVariables ) - da acceso de lectura/escritura a las variables:
vars.get(clave); vars.put(clave,valor); vars.putObject("OBJ1",nuevo Objeto()); vars.getObject("OBJ2"); - accesorios
- (JMeterProperties - clase java.util.Properties ) - por ejemplo, props.get("START.HMS"); props.put("PROP1","1234");
- muestraResultado , anterior
- ( SampleResult ) - da acceso a SampleResult
- evento de muestra
- ( SampleEvent ) - da acceso al SampleEvent
- dechado
- ( Sampler )- da acceso a la última muestra
- AFUERA
- System.out - por ejemplo, OUT.println("mensaje")
Para obtener detalles de todos los métodos disponibles en cada una de las variables anteriores, consulte el Javadoc
Generar resultados resumidos ¶
# Defina la siguiente propiedad para iniciar automáticamente un resúmen con ese nombre # (se aplica solo al modo CLI) #resumen.name=resumen # # intervalo entre resúmenes (en segundos) por defecto 3 minutos #resumen.intervalo=30 # # Escribir mensajes en el archivo de registro #resumen.log=true # # Escribir mensajes en System.out #resumen.out=trueEste elemento está diseñado principalmente para ejecuciones por lotes (CLI). La salida se parece a lo siguiente:
etiqueta + 16 en 0:00:12 = 1,3/s Promedio: 1608 Min: 1163 Max: 2009 Err: 0 (0,00%) Activo: 5 Iniciado: 5 Finalizado: 0 etiqueta + 82 en 0:00:30 = 2,7/s Promedio: 1518 Min: 1003 Max: 2020 Err: 0 (0,00%) Activo: 5 Iniciado: 5 Finalizado: 0 etiqueta = 98 en 0:00:42 = 2,3/s Promedio: 1533 Min: 1003 Max: 2020 Err: 0 (0,00 %) etiqueta + 85 en 0:00:30 = 2,8/s Promedio: 1505 Min: 1008 Max: 2005 Err: 0 (0,00%) Activo: 5 Iniciado: 5 Finalizado: 0 etiqueta = 183 en 0:01:13 = 2,5/s Promedio: 1520 Min: 1003 Max: 2020 Err: 0 (0,00 %) etiqueta + 79 en 0:00:30 = 2,7/s Promedio: 1578 Min: 1089 Max: 2012 Err: 0 (0,00%) Activo: 5 Iniciado: 5 Finalizado: 0 etiqueta = 262 en 0:01:43 = 2,6/s Promedio: 1538 Min: 1003 Max: 2020 Err: 0 (0,00 %) etiqueta + 80 en 0:00:30 = 2,7/s Promedio: 1531 Min: 1013 Max: 2014 Err: 0 (0,00%) Activo: 5 Iniciado: 5 Finalizado: 0 etiqueta = 342 en 0:02:12 = 2,6/s Promedio: 1536 Min: 1003 Max: 2020 Err: 0 (0,00 %) etiqueta + 83 en 0:00:31 = 2,7/s Promedio: 1512 Min: 1003 Max: 1982 Err: 0 (0,00%) Activo: 5 Iniciado: 5 Finalizado: 0 etiqueta = 425 en 0:02:43 = 2,6/s Promedio: 1531 Min: 1003 Max: 2020 Err: 0 (0,00 %) etiqueta + 83 en 0:00:29 = 2,8/s Promedio: 1487 Min: 1023 Max: 2013 Err: 0 (0,00%) Activo: 5 Iniciado: 5 Finalizado: 0 etiqueta = 508 en 0:03:12 = 2,6/s Promedio: 1524 Min: 1003 Max: 2020 Err: 0 (0,00 %) etiqueta + 78 en 0:00:30 = 2,6/s Promedio: 1594 Min: 1013 Max: 2016 Err: 0 (0,00%) Activo: 5 Iniciado: 5 Finalizado: 0 etiqueta = 586 en 0:03:43 = 2,6/s Promedio: 1533 Min: 1003 Max: 2020 Err: 0 (0,00 %) etiqueta + 80 en 0:00:30 = 2,7/s Promedio: 1516 Min: 1013 Max: 2005 Err: 0 (0,00%) Activo: 5 Iniciado: 5 Finalizado: 0 etiqueta = 666 en 0:04:12 = 2,6/s Promedio: 1531 Min: 1003 Max: 2020 Err: 0 (0,00 %) etiqueta + 86 en 0:00:30 = 2,9/s Promedio: 1449 Min: 1004 Max: 2017 Err: 0 (0,00%) Activo: 5 Iniciado: 5 Finalizado: 0 etiqueta = 752 en 0:04:43 = 2,7/s Promedio: 1522 Min: 1003 Max: 2020 Err: 0 (0,00 %) etiqueta + 65 en 0:00:24 = 2,7/s Promedio: 1579 Min: 1007 Max: 2003 Err: 0 (0,00%) Activo: 0 Iniciado: 5 Finalizado: 5 etiqueta = 817 en 0:05:07 = 2,7/s Promedio: 1526 Min: 1003 Max: 2020 Err: 0 (0,00 %)La " etiqueta " es el nombre del elemento. El "+" significa que la línea es una línea delta, es decir, muestra los cambios desde la última salida.
El "=" significa que la línea es una línea total, es decir, muestra el total acumulado.
Las entradas en el archivo de registro de JMeter también incluyen marcas de tiempo. El ejemplo " 817 en 0:05:07 = 2,7/s " significa que hubo 817 muestras grabadas en 5 minutos y 7 segundos, y eso da como resultado 2,7 muestras por segundo.
Los tiempos Avg (Promedio), Min (Mínimo) y Max (Máximo) están en milisegundos.
" Err " significa número de errores (también se muestra como porcentaje).
Las dos últimas líneas aparecerán al final de una prueba. No se sincronizarán con el límite de tiempo adecuado. Tenga en cuenta que los deltas inicial y final pueden ser menores que el intervalo (en el ejemplo anterior, esto es 30 segundos). El primer delta generalmente será más bajo, ya que JMeter se sincroniza con el límite del intervalo. El último delta será más bajo, ya que la prueba generalmente no terminará en un límite de intervalo exacto.
La etiqueta se utiliza para agrupar los resultados de las muestras. Entonces, si tiene varios grupos de subprocesos y desea resumirlos todos, use la misma etiqueta o agregue el resumen al plan de prueba (para que todos los grupos de subprocesos estén dentro del alcance). Se pueden implementar diferentes agrupaciones de resumen utilizando etiquetas adecuadas y agregando los resúmenes a las partes apropiadas del plan de prueba.
Esto no es un error, sino una elección de diseño que permite resumir entre grupos de subprocesos.

Parámetros ¶
Visualizador de Aserción de Comparación ¶

Parámetros ¶
Oyente de fondo ¶

Parámetros ¶
Los siguientes parámetros se aplican a la implementación de GraphiteBackendListenerClient :
Parámetros ¶
Consulte también Resultados en tiempo real para obtener más detalles.

Desde JMeter 3.2, una implementación que permite escribir directamente en InfluxDB con un esquema personalizado. Se llama InfluxdbBackendListenerClient . Los siguientes parámetros se aplican a la implementación de InfluxdbBackendListenerClient :
Parámetros ¶
Consulte también los resultados en tiempo real y las anotaciones de Influxdb en Grafana para obtener más detalles. También hay una subsección sobre cómo configurar el oyente para InfluxDB v2 .
Desde JMeter 5.4, una implementación que escribe todos los resultados de muestra en InfluxDB. Se llama InfluxDBRawBackendListenerClient . Vale la pena señalar que esto utilizará más recursos que InfluxdbBackendListenerClient , tanto de JMeter como de InfluxDB debido al aumento de datos y escrituras individuales. Los siguientes parámetros se aplican a la implementación de InfluxDBRawBackendListenerClient :
Parámetros ¶
18.4 Elementos de configuración ¶
Los elementos de configuración se pueden usar para establecer valores predeterminados y variables para su uso posterior por parte de los muestreadores. Tenga en cuenta que estos elementos se procesan al comienzo del ámbito en el que se encuentran, es decir, antes de cualquier muestra en el mismo ámbito.
Configuración del conjunto de datos CSV ¶
CSV Data Set Config se usa para leer líneas de un archivo y dividirlas en variables. Es más fácil de usar que las funciones __CSVRead() y __StringFromFile() . Es muy adecuado para manejar un gran número de variables y también es útil para probar con valores "aleatorios" y únicos.
La generación de valores aleatorios únicos en tiempo de ejecución es costosa en términos de CPU y memoria, por lo tanto, cree los datos antes de la prueba. Si es necesario, los datos "aleatorios" del archivo se pueden usar junto con un parámetro de tiempo de ejecución para crear diferentes conjuntos de valores de cada ejecución, por ejemplo, usando concatenación, que es mucho más económico que generar todo en tiempo de ejecución.
JMeter permite cotizar valores; esto permite que el valor contenga un delimitador. Si " permitir datos entrecomillados " está habilitado, un valor puede estar entre comillas dobles. Estos se eliminan. Para incluir comillas dobles dentro de un campo entre comillas, utilice dos comillas dobles. Por ejemplo:
1,"2,3","4""5" => 1 2,3 4"5
JMeter admite archivos CSV que tienen una línea de encabezado que define los nombres de las columnas. Para habilitar esto, deje el campo " Nombres de variables " vacío. Se debe proporcionar el delimitador correcto.
JMeter admite archivos CSV con datos entrecomillados que incluyen líneas nuevas.
De forma predeterminada, el archivo solo se abre una vez y cada subproceso utilizará una línea diferente del archivo. Sin embargo, el orden en que se pasan las líneas a los subprocesos depende del orden en que se ejecutan, que puede variar entre iteraciones. Las líneas se leen al comienzo de cada iteración de prueba. El nombre de archivo y el modo se resuelven en la primera iteración.
Consulte la descripción del modo Compartir a continuación para obtener opciones adicionales. Si desea que cada subproceso tenga su propio conjunto de valores, deberá crear un conjunto de archivos, uno para cada subproceso. Por ejemplo test1.csv , test2.csv , ..., test n .csv . Use el nombre de archivo test${__threadNum}.csv y establezca el " Modo de compartir " en " Subproceso actual ".
Como caso especial, la cadena " \t " (sin comillas) en el campo delimitador se trata como una tabulación.
Cuando se alcanza el final del archivo ( EOF ), y la opción de reciclaje es verdadera , la lectura comienza nuevamente con la primera línea del archivo.
Si la opción de reciclaje es falsa y stopThread es falso , todas las variables se establecen en <EOF> cuando se alcanza el final del archivo. Este valor se puede cambiar configurando la propiedad JMeter csvdataset.eofstring .
Si la opción Reciclar es falsa y Detener subproceso es verdadero , al llegar a EOF se detendrá el subproceso.

Parámetros ¶
- Todos los subprocesos : (predeterminado) el archivo se comparte entre todos los subprocesos.
- Grupo de subprocesos actual : cada archivo se abre una vez para cada grupo de subprocesos en el que aparece el elemento
- Subproceso actual : cada archivo se abre por separado para cada subproceso
- Identificador : todos los subprocesos que comparten el mismo identificador comparten el mismo archivo. Entonces, por ejemplo, si tiene 4 grupos de subprocesos, podría usar una identificación común para dos o más de los grupos para compartir el archivo entre ellos. O puede usar el número de subproceso para compartir el archivo entre los mismos números de subproceso en diferentes grupos de subprocesos.
Valores predeterminados de solicitud de FTP ¶

Administrador de caché DNS ¶
El elemento DNS Cache Manager permite probar aplicaciones que tienen varios servidores detrás de balanceadores de carga (CDN, etc.), cuando el usuario recibe contenido de diferentes IP. De forma predeterminada, JMeter utiliza la caché de DNS de JVM. Es por eso que solo un servidor del clúster recibe carga. DNS Cache Manager resuelve los nombres de cada subproceso por separado en cada iteración y guarda los resultados de la resolución en su DNS Cache interno, que es independiente de las cachés DNS de JVM y OS.
Se puede usar una asignación para hosts estáticos para simular algo como el archivo /etc/hosts . Estas entradas tendrán preferencia sobre la resolución personalizada. El uso de resolución de DNS personalizado debe estar habilitado si desea utilizar esta asignación.
Digamos que tiene un servidor de prueba, al que desea acceder con un nombre, que (todavía) no está configurado en sus servidores DNS. Para nuestro ejemplo, sería www.example.com para el nombre del servidor, al que desea acceder en la IP del servidor a123.another.example.org .
Puede cambiar su estación de trabajo y agregar una entrada a su archivo /etc/hosts , o el equivalente para su sistema operativo, o agregar una entrada a la tabla de hosts estáticos del Administrador de caché de DNS.
Escriba www.example.com en la primera columna ( Host ) y a123.another.example.org en la segunda columna ( Hostname or IP address ). Como implica el nombre de la segunda columna, incluso podría usar la dirección IP de su servidor de prueba allí.
La dirección IP del servidor de prueba se buscará mediante el solucionador de DNS personalizado. Cuando no se proporciona ninguno, se utilizará el sistema de resolución de DNS del sistema.
Ahora puede usar www.example.com en sus muestras de HTTPClient4 y las solicitudes se realizarán contra a123.another.example.org con todos los encabezados configurados en www.example.com .

Parámetros ¶
Administrador de autorizaciones HTTP ¶
El Administrador de autorización le permite especificar uno o más inicios de sesión de usuario para páginas web que están restringidas mediante la autenticación del servidor. Ve este tipo de autenticación cuando usa su navegador para acceder a una página restringida, y su navegador muestra un cuadro de diálogo de inicio de sesión. JMeter transmite la información de inicio de sesión cuando encuentra este tipo de página.
Es posible que los encabezados de autorización no se muestren en la pestaña " Solicitud " del oyente de vista de árbol . La implementación de Java realiza una autenticación preventiva, pero no devuelve el encabezado de autorización cuando JMeter obtiene los encabezados. La implementación de HttpComponents (HC 4.5.X) por defecto es preventiva desde 3.2 y se mostrará el encabezado. Para deshabilitar esto, configure los valores como se muestra a continuación, en cuyo caso la autenticación solo se realizará en respuesta a un desafío.
En el archivo jmeter.properties establezca httpclient4.auth.preemptive=false

Parámetros ¶
- Java
- BÁSICO
- HttpCliente 4
- BÁSICO , COMPENDIO y Kerberos
Configuración de Kerberos:
Para configurar Kerberos, debe configurar al menos dos propiedades del sistema JVM:
- -Djava.security.krb5.conf=krb5.conf
- -Djava.security.auth.login.config=jaas.conf
También puede configurar esas dos propiedades en el archivo bin/system.properties . Mire los dos archivos de configuración de muestra ( krb5.conf y jaas.conf ) ubicados en la carpeta bin de JMeter para obtener referencias a más documentación y modifíquelos para que coincidan con su configuración de Kerberos.
La delegación de credenciales está deshabilitada de forma predeterminada para SPNEGO. Si desea habilitarlo, puede hacerlo configurando la propiedad kerberos.spnego.delegate_cred en true .
Al generar un SPN para la autenticación Kerberos SPNEGO, IE y Firefox omitirán el número de puerto de la URL. Chrome tiene una opción ( --enable-auth-negotiate-port ) para incluir el número de puerto si difiere de los estándar ( 80 y 443 ). Ese comportamiento se puede emular configurando la siguiente propiedad JMeter como se muestra a continuación.
En jmeter.properties o user.properties , configure:
- kerberos.spnego.strip_port=false
Control S:
- Botón Agregar : agrega una entrada a la tabla de autorizaciones.
- Botón Eliminar : elimina la entrada de la tabla seleccionada actualmente.
- Botón Cargar : cargue una tabla de autorizaciones previamente guardada y agregue las entradas a las entradas de la tabla de autorizaciones existentes.
- Botón Guardar como : guarda la tabla de autorizaciones actual en un archivo.
Descarga este ejemplo. En este ejemplo, creamos un plan de prueba en un servidor local que envía tres solicitudes HTTP, dos que requieren un inicio de sesión y la otra está abierta para todos. Consulte la figura 10 para ver la composición de nuestro Plan de prueba. En nuestro servidor, tenemos un directorio restringido llamado " secreto ", que contiene dos archivos, " index.html " e " index2.html ". Creamos una identificación de inicio de sesión llamada " kevin ", que tiene una contraseña de " spot ". Entonces, en nuestro Administrador de autorizaciones, creamos una entrada para el directorio restringido y un nombre de usuario y contraseña (ver figura 11). Las dos solicitudes HTTP denominadas " SecretPage1 " y " SecretPage2 "/secret/index.html " y " /secret/index2.html ". La otra solicitud HTTP, denominada " NoSecretPage ", realiza una solicitud a " /index.html ".


Cuando ejecutamos el plan de prueba, JMeter busca en la tabla de autorización la URL que está solicitando. Si la URL base coincide con la URL, entonces JMeter pasa esta información junto con la solicitud.
Administrador de caché HTTP ¶
El Administrador de caché HTTP se utiliza para agregar la funcionalidad de almacenamiento en caché a las solicitudes HTTP dentro de su alcance para simular la función de caché del navegador. Cada subproceso de usuario virtual tiene su propio caché. De forma predeterminada, Cache Manager almacenará hasta 5000 elementos en caché por subproceso de usuario virtual, utilizando el algoritmo LRU. Utilice la propiedad " maxSize " para modificar este valor. Tenga en cuenta que cuanto más aumente este valor, más memoria consumirá HTTP Cache Manager, así que asegúrese de adaptar la opción -Xmx JVM en consecuencia.
Si una muestra tiene éxito (es decir, tiene el código de respuesta 2xx ), los valores de Última modificación y Etag (y Expirado , si corresponde) se guardan para la URL. Antes de ejecutar la siguiente muestra, el muestreador verifica si hay una entrada en el caché y, de ser así, se establecen los encabezados condicionales If-Last-Modified y If-None-Match para la solicitud.
Además, si se selecciona la opción " Usar encabezado Cache-Control/Expires ", el valor de Cache-Control / Expires se compara con la hora actual. Si la solicitud es una solicitud GET y la marca de tiempo es futura, la muestra regresa inmediatamente, sin solicitar la URL del servidor remoto. Esto está destinado a emular el comportamiento del navegador. Tenga en cuenta que si el encabezado Cache-Control es " no-cache ", la respuesta se almacenará en caché como precaducada, por lo que generará una solicitud GET condicional. Si Cache-Control tiene cualquier otro valor, el " max-age" La opción de caducidad se procesa para calcular la duración de la entrada; si falta, se usará el encabezado de caducidad; si también falta la entrada, se almacenará en caché como se especifica en RFC 2616, sección 13.2.4, usando la hora de última modificación y la fecha de respuesta.

Parámetros ¶
Administrador de cookies HTTP ¶
El elemento Administrador de cookies tiene dos funciones:
primero, almacena y envía cookies como un navegador web. Si tiene una solicitud HTTP y la respuesta contiene una cookie, el Administrador de cookies almacena automáticamente esa cookie y la utilizará para todas las solicitudes futuras a ese sitio web en particular. Cada subproceso de JMeter tiene su propia "área de almacenamiento de cookies". Entonces, si está probando un sitio web que usa una cookie para almacenar información de sesión, cada subproceso de JMeter tendrá su propia sesión. Tenga en cuenta que dichas cookies no aparecen en la pantalla del Administrador de cookies, pero se pueden ver mediante el Escuchador del árbol de resultados de vista .
JMeter verifica que las cookies recibidas sean válidas para la URL. Esto significa que las cookies de dominio cruzado no se almacenan. Si tiene un comportamiento defectuoso o desea que se utilicen cookies de dominio cruzado, defina la propiedad de JMeter " CookieManager.check.cookies=false ".
Las cookies recibidas se pueden almacenar como variables de subprocesos de JMeter. Para guardar cookies como variables, defina la propiedad " CookieManager.save.cookies=true ". Además, los nombres de las cookies tienen el prefijo " COOKIE_ " antes de almacenarse (esto evita la corrupción accidental de las variables locales). Para volver al comportamiento original, defina la propiedad " CookieManager.name.prefix= " (uno o más espacios). Si está habilitado, el valor de una cookie con el nombre TEST se puede denominar ${COOKIE_TEST} .
En segundo lugar, puede agregar manualmente una cookie al Administrador de cookies. Sin embargo, si hace esto, la cookie será compartida por todos los subprocesos de JMeter.
Tenga en cuenta que dichas cookies se crean con un tiempo de caducidad lejano en el futuro
Las cookies con valores nulos se ignoran de forma predeterminada. Esto se puede cambiar configurando la propiedad JMeter: CookieManager.delete_null_cookies=false . Tenga en cuenta que esto también se aplica a las cookies definidas manualmente; dichas cookies se eliminarán de la pantalla cuando se actualice. Tenga en cuenta también que el nombre de la cookie debe ser único: si se define una segunda cookie con el mismo nombre, reemplazará a la primera.

Parámetros ¶
[Nota: si tiene un sitio web para probar con dirección IPv6, elija HC4CookieHandler (compatible con IPv6)]
El " dominio " es el nombre de host del servidor (sin http:// ); el puerto se ignora actualmente.
Valores predeterminados de solicitud HTTP ¶
Este elemento le permite establecer valores predeterminados que utilizan sus controladores de solicitud HTTP. Por ejemplo, si está creando un plan de prueba con 25 controladores de solicitud HTTP y todas las solicitudes se envían al mismo servidor, puede agregar un solo elemento de valores predeterminados de solicitud HTTP con el campo " Nombre del servidor o IP " completado. Luego , cuando agregue los 25 controladores de solicitud HTTP, deje el campo " Nombre del servidor o IP " vacío. Los controladores heredarán este valor de campo del elemento Valores predeterminados de solicitud HTTP.


Parámetros ¶
Administrador de encabezados HTTP ¶
El Administrador de encabezados le permite agregar o anular encabezados de solicitud HTTP.
JMeter ahora admite múltiples administradores de encabezado . Las entradas del encabezado se fusionan para formar la lista de la muestra. Si una entrada que se fusionará coincide con un nombre de encabezado existente, reemplaza la entrada anterior. Esto permite configurar un conjunto predeterminado de encabezados y aplicar ajustes a muestras particulares. Tenga en cuenta que un valor vacío para un encabezado no elimina un encabezado existente, simplemente reemplaza su valor.

Parámetros ¶
Descarga este ejemplo. En este ejemplo, creamos un plan de prueba que le dice a JMeter que anule el encabezado de solicitud predeterminado " User-Agent " y use una cadena de agente particular de Internet Explorer en su lugar. (ver figuras 12 y 13).


Valores predeterminados de solicitud de Java ¶
El componente Java Request Defaults le permite establecer valores predeterminados para las pruebas de Java. Consulte la solicitud de Java .

Configuración de conexión JDBC ¶

Parámetros ¶
Si realmente desea utilizar la agrupación compartida (¿por qué?), establezca el recuento máximo en el mismo número de subprocesos para asegurarse de que los subprocesos no se esperen entre sí.
La lista de consultas de validación se puede configurar con la propiedad jdbc.config.check.query y son por defecto:
- hsqldb
- seleccione 1 de INFORMACION_ESQUEMA.SYSTEM_USUARIOS
- Oráculo
- seleccione 1 de doble
- DB2
- seleccione 1 de sysibm.sysdummy1
- MySQL o MariaDB
- seleccione 1
- Microsoft SQL Server (controlador MS JDBC)
- seleccione 1
- postgresql
- seleccione 1
- Ingres
- seleccione 1
- derby
- valores 1
- H2
- seleccione 1
- pájaro de fuego
- seleccione 1 de rdb $ base de datos
- exasol
- seleccione 1
La lista de las clases de controlador jdbc preconfiguradas se puede configurar con la propiedad jdbc.config.jdbc.driver.class y son, de forma predeterminada:
- hsqldb
- org.hsqldb.jdbc.JDBCDriver
- Oráculo
- oracle.jdbc.OracleDriver
- DB2
- com.ibm.db2.jcc.DB2Driver
- mysql
- com.mysql.jdbc.Driver
- Microsoft SQL Server (controlador MS JDBC)
- com.microsoft.sqlserver.jdbc.SQLServerDriver o com.microsoft.jdbc.sqlserver.SQLServerDriver
- postgresql
- org.postgresql.Driver
- Ingres
- com.ingres.jdbc.IngresDriver
- derby
- org.apache.derby.jdbc.ClientDriver
- H2
- org.h2.Controlador
- pájaro de fuego
- org.firebirdsql.jdbc.FBDriver
- derbi apache
- org.apache.derby.jdbc.ClientDriver
- MariaDB
- org.mariadb.jdbc.Driver
- SQLite
- org.sqlite.JDBC
- Sybase AES
- net.sourceforge.jtds.jdbc.Driver
- exasol
- com.exasol.jdbc.EXADriver
Diferentes bases de datos y controladores JDBC requieren diferentes configuraciones de JDBC. La URL de la base de datos y la clase del controlador JDBC están definidas por el proveedor de la implementación de JDBC.
Algunas configuraciones posibles se muestran a continuación. Verifique los detalles exactos en la documentación del controlador JDBC.
Si JMeter informa que no hay un controlador adecuado , esto podría significar:
- No se encontró la clase de controlador. En este caso, habrá un mensaje de registro como DataSourceElement: no se pudo cargar el controlador: {nombre de clase} java.lang.ClassNotFoundException: {nombre de clase}
- Se encontró la clase de controlador, pero la clase no admite la cadena de conexión. Esto podría deberse a un error de sintaxis en la cadena de conexión o porque se utilizó un nombre de clase incorrecto.
Si el servidor de la base de datos no se está ejecutando o no se puede acceder a él, JMeter informará una java.net.ConnectException .
A continuación se dan algunos ejemplos de bases de datos y sus parámetros.
- mysql
-
- Clase de conductor
- com.mysql.jdbc.Driver
- URL de la base de datos
- jdbc:mysql://host[:puerto]/nombrebd
- postgresql
-
- Clase de conductor
- org.postgresql.Driver
- URL de la base de datos
- jdbc:postgresql:{nombrebd}
- Oráculo
-
- Clase de conductor
- oracle.jdbc.OracleDriver
- URL de la base de datos
- jdbc:oracle:thin:@//host:puerto/servicio O jdbc:oracle:thin:@(descripción=(dirección=(host={mc-name})(protocolo=tcp)(puerto={port-no} ))(datos_de_conexión=(sid={sid})))
- Ingreso (2006)
-
- Clase de conductor
- ingres.jdbc.IngresDriver
- URL de la base de datos
- jdbc:ingres://host:puerto/db[;attr=valor]
- Microsoft SQL Server (controlador MS JDBC)
-
- Clase de conductor
- com.microsoft.sqlserver.jdbc.SQLServerDriver
- URL de la base de datos
- jdbc:sqlserver://host:puerto;DatabaseName=dbname
- derbi apache
-
- Clase de conductor
- org.apache.derby.jdbc.ClientDriver
- URL de la base de datos
- jdbc:derby://servidor[:puerto]/nombreDeBaseDeDatos[;URLAttributes=valor[;…]]
- MariaDB
-
- Clase de conductor
- org.mariadb.jdbc.Driver
- URL de la base de datos
- jdbc:mariadb://host[:puerto]/dbname[;URLAttributes=valor[;…]]
- Exasol (consulte también la documentación del controlador JDBC )
-
- Clase de conductor
- com.exasol.jdbc.EXADriver
- URL de la base de datos
- jdbc:exa:host[:puerto][;schema=SCHEMA_NAME][;prop_x=value_x]
Configuración del almacén de claves ¶
El elemento de configuración del almacén de claves le permite configurar cómo se cargará el almacén de claves y qué claves utilizará. Este componente generalmente se usa en escenarios de HTTPS en los que no desea tener en cuenta la inicialización del almacén de claves en el tiempo de respuesta.
Para usar este elemento, primero debe configurar un Java Key Store con los certificados de cliente que desea probar, para hacer eso:
- Cree sus certificados con la utilidad Java keytool o a través de su PKI
- Si fue creado por PKI, importe sus claves en Java Key Store convirtiéndolas a un formato aceptable por JKS
- Luego haga referencia al archivo de almacén de claves a través de las dos propiedades de JVM (o agréguelas en system.properties ):
- -Djavax.net.ssl.keyStore=ruta_al_almacén de claves
- -Djavax.net.ssl.keyStorePassword=contraseña_del_almacén de claves
Para usar PKCS11 como fuente de la tienda, debe establecer javax.net.ssl.keyStoreType en PKCS11 y javax.net.ssl.keyStore en NONE .

Parámetros ¶
- https.use.cached.ssl.context=false se establece en jmeter.properties o user.properties
- Utiliza la implementación HTTPClient 4 para la solicitud HTTP
Elemento de configuración de inicio de sesión ¶
El elemento de configuración de inicio de sesión le permite agregar o anular la configuración de nombre de usuario y contraseña en los muestreadores que usan nombre de usuario y contraseña como parte de su configuración.

Parámetros ¶
Valores predeterminados de solicitud LDAP ¶
El componente Valores predeterminados de solicitud de LDAP le permite establecer valores predeterminados para las pruebas de LDAP. Consulte la Solicitud LDAP .

Valores predeterminados de solicitud extendida de LDAP ¶
El componente Valores predeterminados de solicitud extendida de LDAP le permite establecer valores predeterminados para pruebas de LDAP extendidas. Consulte la solicitud ampliada de LDAP .

Configuración del muestreador TCP ¶
TCP Sampler Config proporciona datos predeterminados para TCP Sampler

Parámetros ¶
Variables definidas por el usuario ¶
El elemento Variables definidas por el usuario le permite definir un conjunto inicial de variables , al igual que en el Plan de prueba .
Los UDV no deben usarse con funciones que generan resultados diferentes cada vez que se llaman. Solo el resultado de la primera llamada de función se guardará en la variable. Sin embargo, los UDV se pueden usar con funciones como __P() , por ejemplo:
ANFITRIÓN ${__P(anfitrión, host local)}
que definiría la variable " HOST " para tener el valor de la propiedad JMeter " host ", por defecto a " localhost " si no está definido.
Para definir variables durante una ejecución de prueba, consulte Parámetros de usuario . Los UDV se procesan en el orden en que aparecen en el Plan, de arriba a abajo.
Para simplificar, se sugiere que los UDV se coloquen solo al comienzo de un grupo de subprocesos (o tal vez debajo del plan de prueba).
Una vez que se han procesado el plan de prueba y todos los UDV, el conjunto de variables resultante se copia en cada subproceso para proporcionar el conjunto de variables inicial.
Si un elemento de tiempo de ejecución, como un preprocesador de parámetros de usuario o un extractor de expresiones regulares, define una variable con el mismo nombre que una de las variables de UDV, esto reemplazará el valor inicial y todos los demás elementos de prueba en el subproceso verán el valor actualizado. valor.

Parámetros ¶
Variable aleatoria ¶
El elemento de configuración de variable aleatoria se utiliza para generar cadenas numéricas aleatorias y almacenarlas en variable para su uso posterior. Es más simple que usar Variables definidas por el usuario junto con la función __Random() .
La variable de salida se construye usando el generador de números aleatorios y luego el número resultante se formatea usando la cadena de formato. El número se calcula usando la fórmula mínimo+Aleatorio.nextInt(máximo-mínimo+1) . Random.nextInt() requiere un entero positivo. Esto significa que máximo-mínimo , es decir, el rango, debe ser inferior a 2147483647 ; sin embargo, los valores mínimo y máximo pueden ser valores largos siempre que el rango sea correcto.

Parámetros ¶
Contador ¶
Permite al usuario crear un contador al que se puede hacer referencia en cualquier parte del grupo de subprocesos. La configuración del contador permite al usuario configurar un punto de partida, un máximo y el incremento. El contador realizará un ciclo desde el inicio hasta el máximo, y luego comenzará de nuevo con el inicio, continuando así hasta que finalice la prueba.
El contador usa un largo para almacenar el valor, por lo que el rango es de -2^63 a 2^63-1 .

Parámetros ¶
Elemento de configuración simple ¶
El elemento de configuración simple le permite agregar o anular valores arbitrarios en muestras. Puede elegir el nombre del valor y el valor en sí. Aunque algunos usuarios aventureros pueden encontrar un uso para este elemento, está aquí principalmente para desarrolladores como una GUI básica que pueden usar mientras desarrollan nuevos componentes de JMeter.

Parámetros ¶
Configuración de origen de MongoDB (DEPRECATED) ¶
Luego puede acceder al objeto com.mongodb.DB en Beanshell o JSR223 Test Elements a través del elemento MongoDBHolder usando este código
importar com.mongodb.DB;
importar org.apache.jmeter.protocol.mongodb.config.MongoDBHolder;
DB db = MongoDBHolder.getDBFromSource("valor de la propiedad MongoDB Source",
"valor de la propiedad Nombre de la base de datos");
…

Parámetros ¶
Hay una cantidad máxima de tiempo para seguir intentándolo, que es de 15 segundos de forma predeterminada.
Esto puede ser útil para evitar que se generen algunas excepciones cuando un servidor está inactivo temporalmente al bloquear las operaciones.
También puede ser útil suavizar la transición a un nuevo nodo principal (para que se elija un nuevo nodo principal dentro del tiempo de reintento).
- para un conjunto de réplicas, el controlador intentará conectarse al antiguo nodo principal para ese momento, en lugar de conmutar por error al nuevo de inmediato
- esto no evita que se generen excepciones en las operaciones de lectura/escritura en el socket, que debe manejar la aplicación.
Se usa únicamente cuando se establece una nueva conexión . Socket.connect(java.net.SocketAddress, int)
El valor predeterminado es 0 y significa que no hay tiempo de espera.
El valor predeterminado es 0 , lo que significa usar los 15 predeterminados si autoConnectRetry está activado.
El valor predeterminado es 120 000 .
El valor predeterminado es 0 y significa que no hay tiempo de espera.
El valor predeterminado es falso .
Todos los subprocesos posteriores obtendrán una excepción de inmediato.
Por ejemplo, si connectionsPerHost es 10 y threadsAllowedToBlockForConnectionMultiplier es 5 , hasta 50 subprocesos pueden esperar una conexión.
El valor predeterminado es 5 .
Si se especifica w , wtimeout , fsync o j , esta configuración se ignora.
El valor predeterminado es falso .
El valor predeterminado es falso .
El valor predeterminado es falso .
El valor predeterminado es 0 .
El valor predeterminado es 0 .
Configuración de conexión de pernos ¶

Parámetros ¶
18.5 Aserciones ¶
Las aserciones se utilizan para realizar comprobaciones adicionales en los muestreadores y se procesan después de cada muestreador en el mismo ámbito. Para asegurarse de que una afirmación se aplique solo a una muestra en particular, agréguela como elemento secundario de la muestra.
Las afirmaciones se pueden aplicar a la muestra principal, a las submuestras o a ambas. El valor predeterminado es aplicar la aserción solo a la muestra principal. Si la afirmación admite esta opción, habrá una entrada en la GUI similar a la siguiente:


Si un submuestreador falla y la muestra principal tiene éxito, la muestra principal se establecerá en estado fallido y se agregará un resultado de afirmación. Si se utiliza la opción de variable JMeter, se supone que se relaciona con la muestra principal y cualquier falla se aplicará solo a la muestra principal.
Aserción de respuesta ¶
El panel de control de aserción de respuesta le permite agregar cadenas de patrones para compararlas con varios campos de la solicitud o respuesta. Las cadenas de patrón son:
- Contiene , coincide con: expresiones regulares de estilo Perl5
- Equals , Substring : texto sin formato, distingue entre mayúsculas y minúsculas
Puede encontrar un resumen de los caracteres de coincidencia de patrones en Expresiones regulares de ORO Perl5.
También puede elegir si se espera que las cadenas coincidan con la respuesta completa o si se espera que la respuesta solo contenga el patrón. Puede adjuntar múltiples aserciones a cualquier controlador para mayor flexibilidad.
Tenga en cuenta que la cadena de patrón no debe incluir los delimitadores adjuntos, es decir, use Price: \d+ no /Price: \d+/ .
De forma predeterminada, el patrón está en modo multilínea, lo que significa que el metacarácter " . " no coincide con la nueva línea. En el modo de varias líneas, " ^ " y " $ " coinciden con el inicio o el final de cualquier línea en cualquier parte de la cadena, no solo con el inicio y el final de toda la cadena. Tenga en cuenta que \s coincide con la nueva línea. El caso también es significativo. Para anular esta configuración, se puede usar la sintaxis de expresión regular extendida . Por ejemplo:
- (?i)
- ignorar caso
- (?s)
- tratar el destino como una sola línea, es decir, " . " coincide con la nueva línea
- (?es)
- tanto lo anterior
- (?i)Pastel de manzana(?-i)
- Coincide con " Apple Pie ", pero no con " Apple Pie " .
- (?s)Manzana.+?Pastel
- coincide con Apple seguido de Pie , que puede estar en una línea posterior.
- Manzana(?s).+?Pastel
- Lo mismo que arriba, pero probablemente sea más claro usar (?s) al principio.

Parámetros ¶
- Solo muestra principal : solo se aplica a la muestra principal
- Solo submuestras: solo se aplica a las submuestras
- Muestra principal y submuestras : se aplica a ambas.
- Nombre de la variable JMeter a usar : la aserción se debe aplicar al contenido de la variable nombrada
- Respuesta de texto : el texto de respuesta del servidor, es decir, el cuerpo, sin incluir los encabezados HTTP.
- Datos de la solicitud: el texto de la solicitud enviado al servidor, es decir, el cuerpo, sin incluir los encabezados HTTP.
- Código de respuesta - por ejemplo, 200
- Mensaje de respuesta - por ejemplo, OK
- Encabezados de respuesta , incluidos los encabezados de conjunto de cookies (si corresponde)
- Encabezados de solicitud
- URL muestreada
- Documento (texto) : el texto extraído de varios tipos de documentos a través de Apache Tika (consulte la sección Ver el documento del árbol de resultados ).
El éxito general de la muestra se determina combinando el resultado de la afirmación con el estado de respuesta existente. Cuando se selecciona la casilla de verificación Ignorar estado , el estado de respuesta se fuerza a correcto antes de evaluar la afirmación.
Las respuestas HTTP con estados en los rangos 4xx y 5xx normalmente se consideran fallidas. La casilla de verificación " Ignorar estado " se puede utilizar para establecer el estado como correcto antes de realizar más comprobaciones. Tenga en cuenta que esto tendrá el efecto de eliminar cualquier error de aserción anterior, así que asegúrese de que esto solo esté configurado en la primera aserción.- Contiene : verdadero si el texto contiene el patrón de expresión regular
- Coincidencias : verdadero si todo el texto coincide con el patrón de expresión regular
- Es igual a: verdadero si todo el texto es igual a la cadena del patrón (se distingue entre mayúsculas y minúsculas)
- Subcadena : verdadero si el texto contiene la cadena de patrón (se distingue entre mayúsculas y minúsculas)
El patrón es una expresión regular de estilo Perl5, pero sin los corchetes que lo encierran.




Afirmación de duración ¶
La afirmación de duración prueba que cada respuesta se recibió dentro de un período de tiempo determinado. Cualquier respuesta que tarde más que el número dado de milisegundos (especificado por el usuario) se marca como una respuesta fallida.

Parámetros ¶
Afirmación de tamaño ¶
La afirmación de tamaño prueba que cada respuesta contiene el número correcto de bytes. Puede especificar que el tamaño sea igual, mayor que, menor que o no igual a un número determinado de bytes.

Parámetros ¶
- Solo muestra principal : la afirmación solo se aplica a la muestra principal
- Solo submuestras: la afirmación solo se aplica a las submuestras
- Muestra principal y submuestras : la afirmación se aplica a ambas.
- Nombre de la variable JMeter a usar : la aserción se debe aplicar al contenido de la variable nombrada
Aserción XML ¶
La aserción XML prueba que los datos de respuesta consisten en un documento XML formalmente correcto. No valida el XML basado en un DTD o esquema ni realiza ninguna otra validación.

Parámetros ¶
Afirmación BeanShell ¶
La aserción BeanShell permite al usuario realizar una verificación de aserciones utilizando un script BeanShell.
Para obtener detalles completos sobre el uso de BeanShell, consulte el sitio web de BeanShell.
Tenga en cuenta que se utiliza un intérprete diferente para cada aparición independiente de la aserción en cada subproceso en un script de prueba, pero se utiliza el mismo intérprete para invocaciones posteriores. Esto significa que las variables persisten en las llamadas a la aserción.
Todas las afirmaciones se llaman desde el mismo subproceso que la muestra.
Si se define la propiedad " beanshell.assertion.init ", se pasa al intérprete como el nombre de un archivo fuente. Esto se puede utilizar para definir métodos y variables comunes. Hay un archivo de inicio de muestra en el directorio bin : BeanShellAssertion.bshrc
El elemento de prueba admite los métodos ThreadListener y TestListener . Estos deben definirse en el archivo de inicialización. Consulte el archivo BeanShellListeners.bshrc para ver definiciones de ejemplo.

Parámetros ¶
- Parámetros : cadena que contiene los parámetros como una sola variable
- bsh.args : matriz de cadenas que contiene parámetros, dividida en espacios en blanco
Hay un script de muestra que puede probar.
Antes de invocar el script, se configuran algunas variables en el intérprete BeanShell. Estas son cadenas a menos que se indique lo contrario:
- log : el objeto registrador . (p. ej.) log.warn("Mensaje"[,Lanzable])
- SampleResult , anterior - el objeto SampleResult ; leer escribir
- Respuesta - el Objeto de respuesta; leer escribir
- Fallo - booleano; leer escribir; se utiliza para establecer el estado de la afirmación
- mensaje de error : cadena; leer escribir; utilizado para configurar el mensaje de afirmación
- ResponseData : el cuerpo de la respuesta (byte [])
- Código de respuesta - por ejemplo, 200
- Mensaje de respuesta - por ejemplo, OK
- ResponseHeaders : contiene los encabezados HTTP
- RequestHeaders : contiene los encabezados HTTP enviados al servidor
- Etiqueta de muestra
- SamplerData : datos que se enviaron al servidor
- ctx - JMeterContext
-
vars - JMeterVariables - por ejemplo
vars.get("VAR1"); vars.put("VAR2","valor"); vars.putObject("OBJ1",nuevo Objeto()); -
accesorios - JMeterProperties (clase java.util.Properties ) - por ejemplo
props.get("INICIO.HMS"); props.put("PROP1","1234");
Los siguientes métodos del objeto Respuesta pueden ser útiles:
- setStopThread(booleano)
- setStopTest(booleano)
- Cadena getSampleLabel()
- setSampleLabel(Cadena)
Afirmación MD5Hex ¶
La afirmación MD5Hex permite al usuario verificar el hash MD5 de los datos de respuesta.

Parámetros ¶
Aserción HTML ¶
La aserción HTML permite al usuario verificar la sintaxis HTML de los datos de respuesta utilizando JTidy.

Parámetros ¶
Aserción XPath ¶
La aserción XPath prueba un documento para ver si está bien formado, tiene la opción de validar contra un DTD o pasar el documento a través de JTidy y probar un XPath. Si ese XPath existe, la afirmación es verdadera. El uso de " / " coincidirá con cualquier documento bien formado y es la expresión XPath predeterminada. La aserción también admite expresiones booleanas, como " count(//*error)=2 ". Consulte http://www.w3.org/TR/xpath para obtener más información sobre XPath.
Algunas expresiones de muestra:- //title[text()='Text to match'] - coincide con <title>Text to match</title> en cualquier parte de la respuesta
- /title[text()='Text to match'] - coincide con <title>Text to match</title> en el nivel raíz de la respuesta

Parámetros ¶
Como una ronda de trabajo para las limitaciones de espacio de nombres del analizador Xalan XPath (implementación en la que se basa JMeter), debe:
- proporcione un archivo de propiedades (si, por ejemplo, su archivo se llama namespaces.properties ) que contiene asignaciones para los prefijos de espacio de nombres:
prefijo1=http\://foo.apache.org prefijo2=http\://toto.apache.org …
- haga referencia a este archivo en el archivo user.properties usando la propiedad:
xpath.namespace.config=espacios de nombres.propiedades
Aserción XPath2 ¶
La aserción XPath2 comprueba la buena formación de un documento. El uso de " / " coincidirá con cualquier documento bien formado y es la expresión XPath2 predeterminada. La aserción también admite expresiones booleanas, como " count(//*error)=2 ".
Algunas expresiones de muestra:- //title[text()='Text to match'] - coincide con <title>Text to match</title> en cualquier parte de la respuesta
- /title[text()='Text to match'] - coincide con <title>Text to match</title> en el nivel raíz de la respuesta
Parámetros ¶
Aserción de esquema XML ¶
La aserción de esquema XML permite al usuario validar una respuesta contra un esquema XML.

Parámetros ¶
Aserción JSR223 ¶
La aserción JSR223 permite utilizar el código de secuencia de comandos JSR223 para comprobar el estado de la muestra anterior.
Parámetros ¶
- Parámetros : cadena que contiene los parámetros como una sola variable
- args : matriz de cadenas que contiene parámetros, dividida en espacios en blanco
Las siguientes variables están configuradas para que las use el script:
- log - ( Registrador ) - se puede usar para escribir en el archivo de registro
- Etiqueta : la etiqueta de cadena
- Nombre de archivo : el nombre del archivo de script (si corresponde)
- Parámetros : los parámetros (como una cadena)
- args : los parámetros como una matriz de cadenas (divididos en espacios en blanco)
- ctx - ( JMeterContext ) - da acceso al contexto
-
vars - ( JMeterVariables ) - otorga acceso de lectura/escritura a las variables:
vars.get(clave); vars.put(clave,valor); vars.putObject("OBJ1",nuevo Objeto()); vars.getObject("OBJ2"); -
accesorios - (JMeterProperties - clase java.util.Properties ) - por ejemplo
props.get("INICIO.HMS"); props.put("PROP1","1234"); - SampleResult , prev - ( SampleResult ) - da acceso al SampleResult anterior (si lo hay)
- sampler - ( Sampler ) - da acceso a la muestra actual
- OUT - System.out - por ejemplo, OUT.println("mensaje")
- AssertionResult - ( AssertionResult ) - el resultado de la aserción
El script puede verificar varios aspectos del SampleResult . Si se detecta un error, el script debe usar AssertionResult.setFailureMessage("message") y AssertionResult.setFailure(true) .
Para obtener más detalles de todos los métodos disponibles en cada una de las variables anteriores, consulte el Javadoc
Comparar aserción ¶

Parámetros ¶
Afirmación SMIME ¶
- bcmail-xxx.jar (Castillo hinchable SMIME/CMS)
- bcprov-xxx.jar (Proveedor de castillo hinchable)
Si usa Mail Reader Sampler , asegúrese de seleccionar " Almacenar el mensaje usando MIME (sin formato) ", de lo contrario, la afirmación no podrá procesar el mensaje correctamente.

Parámetros ¶
Aserción JSON ¶
Este componente te permite realizar validaciones de documentos JSON. Primero, analizará el JSON y fallará si los datos no son JSON. En segundo lugar, buscará la ruta especificada, utilizando la sintaxis de Jayway JsonPath 1.2.0 . Si no se encuentra la ruta, fallará. En tercer lugar, si se encontró la ruta JSON en el documento y se solicitó la validación contra el valor esperado, realizará la validación. Para el valor nulo , hay una casilla de verificación especial en la GUI. Tenga en cuenta que si la ruta devolverá un objeto de matriz, se repetirá y si se encuentra el valor esperado, la afirmación tendrá éxito. Para validar el uso de matriz vacía []cuerda. Además, si el parche devolverá un objeto de diccionario, se convertirá en una cadena antes de la comparación.

Parámetros ¶
Aserción JSON JMESPath ¶
Este componente le permite realizar aserciones en el contenido de documentos JSON utilizando JMESPath . Primero, analizará el JSON y fallará si los datos no son JSON.
En segundo lugar, buscará la ruta especificada, utilizando la sintaxis JMESPath.
Si no se encuentra la ruta, fallará.
En tercer lugar, si se encontró la ruta JMES en el documento y se solicitó la validación contra el valor esperado, realizará esta verificación adicional. Si desea verificar la nulidad, use la casilla de verificación Esperar nulo .
Tenga en cuenta que la ruta no puede ser nula ya que la expresión JMESPath no se compilará y se producirá un error. Incluso si espera una respuesta vacía o nula, debe colocar una expresión JMESPath válida.

Parámetros ¶
18.6 Temporizadores ¶
Puede aplicar un factor de multiplicación en los retrasos de sueño calculados por el temporizador aleatorio configurando la propiedad timer.factor=float number donde float number es un número decimal positivo.
JMeter multiplicará este factor por el retraso de sueño calculado. Esta característica puede ser utilizada por:
Los temporizadores solo se procesan junto con un muestreador. Un temporizador que no esté en el mismo alcance que una muestra no se procesará en absoluto.
Para aplicar un temporizador a una sola muestra, agregue el temporizador como un elemento secundario de la muestra. El temporizador se aplicará antes de que se ejecute el muestreador. Para aplicar un temporizador después de una muestra, agréguelo a la siguiente muestra o agréguelo como elemento secundario de una muestra de acción de control de flujo .
Temporizador constante ¶
Si desea que cada subproceso se detenga durante la misma cantidad de tiempo entre solicitudes, use este temporizador.

Parámetros ¶
Temporizador aleatorio gaussiano ¶
Este temporizador detiene cada solicitud de subproceso durante un período de tiempo aleatorio, y la mayoría de los intervalos de tiempo ocurren cerca de un valor particular. El retraso total es la suma del valor distribuido de Gauss (con una media de 0,0 y una desviación estándar de 1,0 ) multiplicado por el valor de desviación que especifique y el valor de compensación. Otra forma de explicarlo, en Gaussian Random Timer, la variación alrededor del desplazamiento constante tiene una distribución de curva Gaussiana.

Parámetros ¶
Temporizador aleatorio uniforme ¶
Este temporizador detiene cada solicitud de subproceso durante un período de tiempo aleatorio, y cada intervalo de tiempo tiene la misma probabilidad de ocurrir. El retraso total es la suma del valor aleatorio y el valor de compensación.

Parámetros ¶
Temporizador de rendimiento constante ¶
Este temporizador introduce pausas variables, calculadas para mantener el rendimiento total (en términos de muestras por minuto) lo más cerca posible de una cifra determinada. Por supuesto, el rendimiento será menor si el servidor no es capaz de manejarlo, o si otros temporizadores o elementos de prueba que consumen mucho tiempo lo impiden.
NB aunque el temporizador se denomina temporizador de rendimiento constante, el valor de rendimiento no necesita ser constante. Se puede definir en términos de una llamada de función o variable, y el valor se puede cambiar durante una prueba. El valor se puede cambiar de varias maneras:
- utilizando una variable de contador
- usando una función __jexl3 , __groovy para proporcionar un valor cambiante
- usando el servidor BeanShell remoto para cambiar una propiedad JMeter
Consulte Mejores prácticas para obtener más detalles.

Parámetros ¶
- solo este subproceso : cada subproceso intentará mantener el rendimiento objetivo. El rendimiento general será proporcional al número de subprocesos activos.
- todos los subprocesos activos en el grupo de subprocesos actual : el rendimiento objetivo se divide entre todos los subprocesos activos del grupo. Cada subproceso se retrasará según sea necesario, según la última vez que se ejecutó.
- todos los subprocesos activos : el rendimiento objetivo se divide entre todos los subprocesos activos en todos los grupos de subprocesos. Cada subproceso se retrasará según sea necesario, según la última vez que se ejecutó. En este caso, cada grupo de subprocesos necesitará un temporizador de rendimiento constante con la misma configuración.
- todos los subprocesos activos en el grupo de subprocesos actual (compartido) : como se indicó anteriormente, pero cada subproceso se retrasa según la última vez que se ejecutó cualquier subproceso en el grupo.
- todos los hilos activos (compartidos) - como arriba; cada subproceso se retrasa en función de cuándo se ejecutó por última vez.
Los algoritmos compartidos y no compartidos tienen como objetivo generar el rendimiento deseado y producirán resultados similares.
El algoritmo compartido debería generar una tasa de transacción general más precisa.
El algoritmo no compartido debería generar una distribución más uniforme de transacciones entre subprocesos.
Temporizador de rendimiento preciso ¶
Este temporizador introduce pausas variables, calculadas para mantener el rendimiento total (por ejemplo, en términos de muestras por minuto) lo más cerca posible de una cifra dada. Por supuesto, el rendimiento será menor si el servidor no es capaz de manejarlo, o si otros temporizadores, o si no hay suficientes subprocesos, o elementos de prueba que consumen mucho tiempo lo impiden.
Aunque el temporizador se denomina Temporizador de rendimiento preciso, no tiene como objetivo producir exactamente la misma cantidad de muestras en intervalos de un segundo durante la prueba.
El temporizador funciona mejor para tarifas inferiores a 36000 solicitudes/hora, sin embargo, su kilometraje puede variar (consulte la sección de monitoreo a continuación si sus objetivos son muy diferentes).
La mejor ubicación de un temporizador de rendimiento preciso en un plan de prueba
Como sabrá, los temporizadores son heredados por todos los hermanos y sus elementos secundarios. Es por eso que uno de los mejores lugares para Precise Throughput Timer es debajo del primer elemento en un ciclo de prueba. Por ejemplo, puede agregar una muestra ficticia al principio y colocar el temporizador debajo de esa muestra ficticia.
horario producido
Precise Throughput Timer modela el horario de llegadas de Poisson . Ese cronograma a menudo ocurre en la vida real, por lo que tiene sentido usarlo para las pruebas de carga. Por ejemplo, naturalmente podría generar muestras que están muy juntas, por lo que podría revelar problemas de concurrencia. Incluso si logra generar llegadas de Poisson con Poisson Random Timer , sería susceptible a los problemas que se enumeran a continuación. Por ejemplo, las verdaderas llegadas de Poisson pueden tener una pausa indefinidamente larga y eso no es práctico para las pruebas de carga. Por ejemplo, las llegadas de Poisson "regulares" con una tasa de 1 por segundo podrían terminar con 50 muestras durante una prueba de 60 segundos de duración.
El temporizador de rendimiento constante converge a la tasa especificada, sin embargo, tiende a producir muestras a intervalos regulares.
Pico de aceleración y arranque
Puede usar enfoques de "aumento" o similares para evitar un pico al comienzo de la prueba. Por ejemplo, si configura el Grupo de subprocesos para que tenga 100 subprocesos y establece el Período de aceleración en 0 (o en un número pequeño), entonces todos los subprocesos se iniciarán al mismo tiempo y se producirá un aumento no deseado de la carga. . Además de eso, si configura el Período de aceleración demasiado alto, es posible que haya " muy pocos " subprocesos disponibles al principio para lograr la carga requerida.
Precise Throughput Timer programa las ejecuciones de forma aleatoria, por lo que se puede utilizar para generar una carga constante, y se recomienda configurar tanto el período de aceleración como el retraso en 0 .
Múltiples grupos de subprocesos que comienzan al mismo tiempo
Puede aparecer una variación del problema de aceleración cuando el plan de prueba incluye varios grupos de subprocesos . Para mitigar ese problema, generalmente se agrega un retraso "aleatorio" a cada grupo de subprocesos para que los subprocesos comiencen en diferentes momentos.
Precise Throughput Timer evita ese problema ya que programa las ejecuciones de forma aleatoria. No necesita agregar retrasos aleatorios adicionales para mitigar el pico de inicio
Número de iteraciones por hora
Uno de los requisitos básicos es emitir N muestras por M minutos. Que sean 60 iteraciones por hora. Los clientes comerciales no entenderían si informa los resultados de la prueba de carga con 57 ejecuciones "solo porque el azar fue aleatorio". Para generar 60 iteraciones por hora, debe configurar de la siguiente manera (otros parámetros podrían dejarse con sus valores predeterminados)
- Rendimiento objetivo (muestras) : 60
- Período de rendimiento (segundos) : 3600
- Duración de la prueba (segundos) : 3600
Las dos primeras opciones establecen el rendimiento. Aunque 60/3600, 30/1800 y 120/7200 representan exactamente el mismo nivel de carga, elija el que represente mejor los requisitos comerciales. Por ejemplo, si el requisito es probar "60 muestras por hora", configure 60/3600. Si el requisito es probar "1 muestra por minuto", establezca 1/60.
La duración de la prueba (segundos) está ahí, por lo que el temporizador garantiza el número exacto de muestras para una duración de prueba determinada. Precise Throughput Timer crea un programa para las muestras en el inicio de la prueba. Por ejemplo, si desea realizar una prueba de 5 minutos con un rendimiento de 60 por hora, establecería la duración de la prueba (segundos) en 300. Esto permite configurar el rendimiento de una manera amigable para los negocios. Nota: La duración de la prueba (segundos) no limita la duración de la prueba. Es solo una pista para el temporizador.
Número de subprocesos y tiempos de reflexión
Uno de los errores comunes es ajustar la cantidad de subprocesos y los tiempos de reflexión para lograr el rendimiento deseado. Aunque podría funcionar, ese enfoque da como resultado una gran cantidad de tiempo dedicado a las ejecuciones de prueba. Es posible que deba ajustar los hilos y los retrasos nuevamente cuando llegue la nueva versión de la aplicación.
Precise Throughput Timer permite establecer un objetivo de rendimiento e ir a por él sin importar qué tan bien se desempeñe la aplicación. Para hacer eso, Precise Throughput Timer crea un programa en el inicio de la prueba, luego usa ese programa para liberar subprocesos. El principal impulsor de los tiempos de reflexión y la cantidad de subprocesos deben ser los requisitos comerciales, no el deseo de igualar el rendimiento de alguna manera.
Por ejemplo, si su aplicación es utilizada por ingenieros de soporte en un centro de llamadas. Suponga que hay 2 ingenieros en el centro de llamadas y el rendimiento objetivo es 1 por minuto. Suponga que el ingeniero tarda 4 minutos en leer y revisar la página web. Para ese caso, debe configurar 2 subprocesos en el grupo, usar 4 minutos para los retrasos de tiempo de reflexión y especificar 1 por minuto en Precise Throughput Timer . Por supuesto, daría como resultado algo alrededor de 2 muestras/4 minutos = 0,5 por minuto y el resultado de dicha prueba significa que "necesita más ingenieros de soporte en un centro de llamadas" o "necesita reducir el tiempo que le toma a un ingeniero realizar una tarea". ".
Probando tasas bajas y pruebas repetibles
La prueba a tasas bajas (por ejemplo, 60 por hora) requiere conocer el perfil de prueba deseado. Por ejemplo, si necesita inyectar carga a intervalos uniformes (por ejemplo, 60 segundos entre ellos), entonces será mejor que use el Temporizador de rendimiento constante . Sin embargo, si necesita tener un cronograma aleatorio (por ejemplo, para modelar usuarios reales que ejecutan informes), Precise Throughput Timer es su amigo.
Al comparar los resultados de múltiples pruebas de carga, es útil poder repetir exactamente el mismo perfil de prueba. Por ejemplo, si se invoca la acción X (por ejemplo, "Informe de ganancias") después de 5 minutos del inicio de la prueba, sería bueno replicar ese patrón para las ejecuciones de prueba posteriores. La replicación del mismo patrón de carga simplifica el análisis de los resultados de la prueba (por ejemplo, gráfico de porcentaje de CPU).
La semilla aleatoria (cambio de 0 a aleatorio) permite controlar el valor semilla que utiliza Precise Throughput Timer . De forma predeterminada, se inicializa con 0 y eso significa que se utiliza semilla aleatoria para cada ejecución de prueba. Si necesita tener un patrón de carga repetible, cambie la semilla aleatoria para que tenga un valor aleatorio. El consejo general es usar semilla distinta de cero, y "0 por defecto" es un límite de implementación.
Nota: cuando se utilizan varios grupos de subprocesos con las mismas tasas de rendimiento y la misma semilla distinta de cero, es posible que se disparen las muestras al mismo tiempo.
Pruebas de altas tasas y/o largas duraciones de prueba
Precise Throughput Timer genera el programa y lo guarda en la memoria. En la mayoría de los casos, no debería ser un problema, sin embargo, recuerde que es posible que desee mantener el programa por debajo de 1 000 000 de muestras. Se necesitan ~200 ms para generar un programa para 1 000 000 de muestras, y el programa consume 8 megabytes en el montón. El programa para 10 millones de entradas tarda 1-2 segundos en construirse y consume 80 megabytes en el montón.
Por ejemplo, si desea realizar una prueba de 2 semanas de duración con una tasa de 5000 por hora, entonces probablemente desee tener exactamente 5000 muestras por hora. Puede establecer la propiedad Duración de la prueba (segundos) del temporizador en 1 hora. Luego, el temporizador crearía un programa de 5000 muestras durante una hora, y cuando se agote el programa, el temporizador generará un programa para la siguiente hora.
Al mismo tiempo, puede configurar la duración de la prueba (segundos) en 2 semanas y el temporizador generará un programa con 168 000 muestras = 2 semanas * 5 000 muestras/hora = 2*7*24*500 . La programación tardaría ~30 ms en generarse y consumiría un poco más de 1 megabyte.
carga explosiva
Puede haber un caso en el que todas las muestras deban venir en pares, triples, etc. Ciertos casos pueden resolverse mediante el temporizador de sincronización , sin embargo, el temporizador de rendimiento preciso tiene una forma nativa de emitir solicitudes en paquetes. Este comportamiento está deshabilitado de forma predeterminada y se controla con la configuración de "Salidas por lotes".
- Número de subprocesos en el lote (subprocesos) . Especifica el número de muestras en un lote. Tenga en cuenta que la cantidad total de muestras seguirá estando en línea con el rendimiento objetivo
- Retraso entre subprocesos en el lote (ms) . Por ejemplo, si se establece en 42 y el tamaño del lote es 3, los subprocesos partirán en x, x+42ms, x+84ms
Tasa de carga variable
Aunque los valores de las propiedades (por ejemplo, el rendimiento) se pueden definir a través de expresiones, se recomienda mantener el valor más o menos igual durante la prueba, ya que se necesita tiempo para volver a calcular el nuevo programa para adaptar los nuevos valores.
Vigilancia
A medida que se genera el siguiente programa, Precise Throughput Timer registra un mensaje en jmeter.log : 2018-01-04 17:34:03,635 INFO oajtConstantPoissonProcessGenerator: Generado 21 tiempos (... 20 requeridos, tasa 1.0, duración 20, límite exacto 20000, i21) en 0 ms. First 15 events will be fired at: 1.1869653574244292 (+1.1869653574244292), 1.4691340403043207 (+0.2821686828798915), 3.638151706179226 (+2.169017665874905), 3.836357090410566 (+0.19820538423134026), 4.709330071408575 (+0.8729729809980085), 5.61330076999953 (+0.903970698590955), ... Esto muestra que la generación de horarios tomó 0 ms y muestra marcas de tiempo absolutas en segundos. En el caso anterior, la velocidad se estableció en 1 por segundo y las marcas de tiempo reales se convirtieron en 1,2 segundos, 1,5 segundos, 3,6 segundos, 3,8 segundos, 4,7 segundos, etc.

Parámetros ¶
Temporizador de sincronización ¶
El propósito de SyncTimer es bloquear subprocesos hasta que se haya bloqueado una cantidad X de subprocesos, y luego se liberan todos a la vez. Por lo tanto, un SyncTimer puede crear grandes cargas instantáneas en varios puntos del plan de prueba.

Parámetros ¶
Temporizador BeanShell ¶
El temporizador BeanShell se puede utilizar para generar un retraso.
Para obtener detalles completos sobre el uso de BeanShell, consulte el sitio web de BeanShell.
El elemento de prueba admite los métodos ThreadListener y TestListener . Estos deben definirse en el archivo de inicialización. Consulte el archivo BeanShellListeners.bshrc para ver definiciones de ejemplo.

Parámetros ¶
- Parámetros : cadena que contiene los parámetros como una sola variable
- bsh.args : matriz de cadenas que contiene parámetros, dividida en espacios en blanco
Antes de invocar el script, se configuran algunas variables en el intérprete BeanShell:
- log - ( Registrador ) - se puede usar para escribir en el archivo de registro
- ctx - ( JMeterContext ) - da acceso al contexto
-
vars - ( JMeterVariables ) - otorga acceso de lectura/escritura a las variables:
vars.get(clave); vars.put(clave,valor); vars.putObject("OBJ1",nuevo Objeto()); - props - (JMeterProperties - clase java.util.Properties) - por ejemplo, props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - da acceso al SampleResult anterior (si lo hay)
Para obtener detalles de todos los métodos disponibles en cada una de las variables anteriores, consulte el Javadoc
Si se define la propiedad beanshell.timer.init , se usa para cargar un archivo de inicialización, que se puede usar para definir métodos, etc. para usar en el script BeanShell.
Temporizador JSR223 ¶
El temporizador JSR223 se puede usar para generar un retraso usando un lenguaje de secuencias de comandos JSR223,
Parámetros ¶
- Parámetros : cadena que contiene los parámetros como una sola variable
- args : matriz de cadenas que contiene parámetros, dividida en espacios en blanco
Antes de invocar el script, se configuran algunas variables en el intérprete de scripts:
- log - ( Registrador ) - se puede usar para escribir en el archivo de registro
- ctx - ( JMeterContext ) - da acceso al contexto
-
vars - ( JMeterVariables ) - otorga acceso de lectura/escritura a las variables:
vars.get(clave); vars.put(clave,valor); vars.putObject("OBJ1",nuevo Objeto()); - props - (JMeterProperties - clase java.util.Properties) - por ejemplo, props.get("START.HMS"); props.put("PROP1","1234");
- sampler - ( Sampler ) - el Sampler actual
- Etiqueta : el nombre del temporizador
- FileName : el nombre del archivo (si lo hay)
- SALIDA - Sistema.fuera
Para obtener detalles de todos los métodos disponibles en cada una de las variables anteriores, consulte el Javadoc
Temporizador aleatorio Poisson ¶
Este temporizador detiene cada solicitud de subproceso durante un período de tiempo aleatorio, y la mayoría de los intervalos de tiempo ocurren cerca de un valor particular. El retraso total es la suma del valor distribuido de Poisson y el valor de compensación.
Nota: si desea modelar las llegadas de Poisson, considere usar Precise Throughput Timer en su lugar.

Parámetros ¶
18.7 Preprocesadores ¶
Los preprocesadores se utilizan para modificar los Samplers en su alcance.
Analizador de enlaces HTML ¶
Este modificador analiza la respuesta HTML del servidor y extrae enlaces y formularios. Se examinará una muestra de prueba de URL que pase por este modificador para ver si "coincide" con alguno de los enlaces o formularios extraídos de la respuesta inmediatamente anterior. Luego reemplazaría los valores en la muestra de prueba de URL con los valores apropiados del enlace o formulario coincidente. Las expresiones regulares de tipo Perl se utilizan para encontrar coincidencias.

Considere un ejemplo simple: supongamos que desea que JMeter se "arañe" a través de su sitio, presionando enlace tras enlace analizado desde el HTML devuelto por su servidor (esto no es realmente lo más útil que puede hacer, pero sirve como un buen ejemplo) . Crearía un Controlador simple y le agregaría el "Análisis de enlaces HTML". Luego, cree una solicitud HTTP y establezca el dominio en " .* ", y la ruta también. Esto hará que su muestra de prueba coincida con cualquier enlace que se encuentre en las páginas devueltas. Si desea restringir el rastreo a un dominio en particular, cambie el valor del dominio al que desee. Entonces, solo se seguirán los enlaces a ese dominio.
Un ejemplo más útil: dada una aplicación de sondeo web, es posible que tenga una página con varias opciones de sondeo como botones de radio para que el usuario seleccione. Digamos que los valores de las opciones de encuesta son muy dinámicos, tal vez generados por el usuario. Si desea que JMeter pruebe la encuesta, puede crear muestras de prueba con valores codificados de forma rígida o puede dejar que HTML Link Parser analice el formulario e inserte una opción de encuesta aleatoria en su muestra de prueba de URL. Para hacer esto, siga el ejemplo anterior, excepto que, al configurar las opciones de URL de su controlador Web Test, asegúrese de elegir " POST " como método. Ingrese valores codificados para el dominio , la ruta y cualquier parámetro de formulario adicional. Luego, para el parámetro real del botón de radio, ingrese el nombre (digamos que espoll_choice "), y luego " .* " para el valor de ese parámetro. Cuando el modificador examina esta muestra de prueba de URL, encontrará que "coincide" con el formulario de encuesta (y no debería coincidir con ningún otro formulario, dado que ha especificado todos los demás aspectos de la muestra de prueba de URL), y reemplazará los parámetros de su formulario con los parámetros coincidentes del formulario. Dado que la expresión regular " .* " coincidirá con cualquier cosa, el modificador probablemente tendrá una lista de botones de radio para elegir. Elegirá al azar y reemplazará el valor en su muestra de prueba de URL. Cada vez que se realice la prueba, se elegirá un nuevo valor aleatorio.

Modificador de reescritura de URL HTTP ¶
Este modificador funciona de manera similar al Analizador de enlaces HTML, excepto que tiene un propósito específico por el cual es más fácil de usar que el Analizador de enlaces HTML y más eficiente. Para las aplicaciones web que utilizan la reescritura de URL para almacenar ID de sesión en lugar de cookies, este elemento se puede adjuntar en el nivel de ThreadGroup, como el Administrador de cookies HTTP . Simplemente déle el nombre del parámetro de identificación de la sesión, lo encontrará en la página y agregará el argumento a cada solicitud de ese ThreadGroup.
Alternativamente, este modificador se puede adjuntar a solicitudes seleccionadas y solo las modificará. Los usuarios inteligentes incluso determinarán que este modificador se puede usar para capturar valores que eluden el HTML Link Parser .

Parámetros ¶
Parámetros de usuario ¶
Permite al usuario especificar valores para variables de usuario específicas de subprocesos individuales.
Las variables de usuario también se pueden especificar en el plan de prueba, pero no son específicas para subprocesos individuales. Este panel le permite especificar una serie de valores para cualquier variable de usuario. Para cada hilo, a la variable se le asignará uno de los valores de la serie en secuencia. Si hay más subprocesos que valores, los valores se reutilizan. Por ejemplo, esto se puede usar para asignar una identificación de usuario distinta para que la use cada subproceso. Se puede hacer referencia a las variables de usuario en cualquier campo de cualquier componente de JMeter.
La variable se especifica haciendo clic en el botón Agregar variable en la parte inferior del panel y completando el nombre de la variable en la columna ' Nombre: '. Para agregar un nuevo valor a la serie, haga clic en el botón ' Agregar usuario ' y complete el valor deseado en la columna recién agregada.
Se puede acceder a los valores en cualquier componente de prueba en el mismo grupo de subprocesos, usando la sintaxis de función : ${variable} .
Consulte también el elemento de configuración del conjunto de datos CSV , que es más adecuado para una gran cantidad de parámetros.

Parámetros ¶
Preprocesador BeanShell ¶
El preprocesador BeanShell permite aplicar código arbitrario antes de tomar una muestra.
Para obtener detalles completos sobre el uso de BeanShell, consulte el sitio web de BeanShell.
El elemento de prueba admite los métodos ThreadListener y TestListener . Estos deben definirse en el archivo de inicialización. Consulte el archivo BeanShellListeners.bshrc para ver definiciones de ejemplo.

Parámetros ¶
- Parámetros : cadena que contiene los parámetros como una sola variable
- bsh.args : matriz de cadenas que contiene parámetros, dividida en espacios en blanco
Antes de invocar el script, se configuran algunas variables en el intérprete BeanShell:
- log - ( Registrador ) - se puede usar para escribir en el archivo de registro
- ctx - ( JMeterContext ) - da acceso al contexto
-
vars - ( JMeterVariables ) - otorga acceso de lectura/escritura a las variables:
vars.get(clave); vars.put(clave,valor); vars.putObject("OBJ1",nuevo Objeto()); - props - (JMeterProperties - clase java.util.Properties) - por ejemplo, props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - da acceso al SampleResult anterior (si lo hay)
- sampler - ( Sampler )- da acceso a la muestra actual
Para obtener detalles de todos los métodos disponibles en cada una de las variables anteriores, consulte el Javadoc
Si se define la propiedad beanshell.preprocessor.init , se usa para cargar un archivo de inicialización, que se puede usar para definir métodos, etc. para usar en el script BeanShell.
Preprocesador JSR223 ¶
El preprocesador JSR223 permite aplicar el código de script JSR223 antes de tomar una muestra.
Parámetros ¶
- Parámetros : cadena que contiene los parámetros como una sola variable
- args : matriz de cadenas que contiene parámetros, dividida en espacios en blanco
Las siguientes variables JSR223 están configuradas para que las use el script:
- log - ( Registrador ) - se puede usar para escribir en el archivo de registro
- Etiqueta : la etiqueta de cadena
- FileName : el nombre del archivo de script (si lo hay)
- Parámetros : los parámetros (como una cadena)
- args : los parámetros como una matriz de cadenas (divididos en espacios en blanco)
- ctx - ( JMeterContext ) - da acceso al contexto
-
vars - ( JMeterVariables ) - otorga acceso de lectura/escritura a las variables:
vars.get(clave); vars.put(clave,valor); vars.putObject("OBJ1",nuevo Objeto()); vars.getObject("OBJ2"); - props - (JMeterProperties - clase java.util.Properties) - por ejemplo, props.get("START.HMS"); props.put("PROP1","1234");
- sampler - ( Sampler )- da acceso a la muestra actual
- OUT - System.out - por ejemplo, OUT.println("mensaje")
Para obtener detalles de todos los métodos disponibles en cada una de las variables anteriores, consulte el Javadoc
Preprocesador JDBC ¶
El preprocesador de JDBC le permite ejecutar alguna instrucción SQL justo antes de que se ejecute una muestra. Esto puede ser útil si su muestra JDBC requiere que algunos datos estén en la base de datos y no puede calcularlos en un grupo de subprocesos de configuración. Para obtener más información, consulte Solicitud de JDBC .
Consulte el siguiente plan de prueba:
En el plan de prueba vinculado, " Crear precio de corte " JDBC PreProcessor llama a un procedimiento almacenado para crear un precio de corte en la base de datos, este será utilizado por " Calcular precio de corte ".

Parámetros de usuario RegEx ¶
Permite especificar valores dinámicos para parámetros HTTP extraídos de otra solicitud HTTP utilizando expresiones regulares. Los parámetros de usuario RegEx son específicos para subprocesos individuales.
Este componente le permite especificar el nombre de referencia de una expresión regular que extrae los nombres y valores de los parámetros de solicitud HTTP. Se deben especificar números de grupos de expresiones regulares para el nombre del parámetro y también para el valor del parámetro. El reemplazo solo ocurrirá para los parámetros en el muestreador que usa estos parámetros de usuario RegEx cuyo nombre coincide

Parámetros ¶
Supongamos que tenemos una solicitud que devuelve un formulario con 3 parámetros de entrada y queremos extraer el valor de 2 de ellos para inyectarlos en la próxima solicitud.
- Crear expresión regular de posprocesador para la primera solicitud HTTP
- refName : establece el nombre de una expresión regular Expresión ( listParams )
-
expresión regular - expresión que extraerá los nombres de entrada y los atributos de los valores de entrada
Ej: input name="([^"]+?)" value="([^"]+?)" - plantilla - estaría vacía
- match nr - -1 (para iterar a través de todas las coincidencias posibles)
- Crear parámetros de usuario RegEx de preprocesador para la segunda solicitud HTTP
- refName : establezca el mismo nombre de referencia de una expresión regular, sería listParams en nuestro ejemplo
- número de grupo de nombres de parámetros - número de grupo de expresión regular para nombres de parámetros, sería 1 en nuestro ejemplo
- número de grupo de valores de parámetro - número de grupo de expresión regular para valores de parámetro, sería 2 en nuestro ejemplo
Consulte también el elemento Extractor de expresiones regulares , que se utiliza para extraer nombres y valores de parámetros.
Tiempo de espera de muestra ¶
Este preprocesador programa una tarea de temporizador para interrumpir una muestra si tarda demasiado en completarse. El tiempo de espera se ignora si es cero o negativo. Para que esto funcione, el muestreador debe implementar Interruptible. Se sabe que los siguientes muestreadores lo hacen:
AJP, BeanShell, FTP, HTTP, Soap, AccessLog, MailReader, JMS Subscriber, TCPSampler, TestAction, JavaSampler
El elemento de prueba está diseñado para usarse cuando los tiempos de espera individuales, como el tiempo de espera de conexión o el tiempo de espera de respuesta, son insuficientes, o cuando el muestreador no admite tiempos de espera. El tiempo de espera debe establecerse lo suficientemente largo para que no se active en las pruebas normales, pero lo suficientemente corto para que interrumpa las muestras que están atascadas.
[Por defecto, JMeter usa un Callable para interrumpir la muestra. Esto se ejecuta en el mismo subproceso que el temporizador, por lo que si la interrupción tarda mucho tiempo, puede retrasar el procesamiento de los tiempos de espera posteriores. No se espera que esto sea un problema, pero si es necesario, la propiedad InterruptTimer.useRunnable se puede establecer en verdadero para usar un subproceso Runnable separado en lugar de Callable.]

Parámetros ¶
18.8 Post-procesadores ¶
Como sugiere el nombre, los posprocesadores se aplican después de las muestras. Tenga en cuenta que se aplican a todos los muestreadores en el mismo ámbito, por lo que para asegurarse de que un posprocesador se aplique solo a un muestreador en particular, agréguelo como elemento secundario del muestreador.
Los posprocesadores se ejecutan antes de las afirmaciones, por lo que no tienen acceso a ningún resultado de afirmación, ni el estado de la muestra reflejará los resultados de ninguna afirmación. Si necesita acceso a los resultados de la aserción, intente usar un oyente en su lugar. También tenga en cuenta que la variable JMeterThread.last_sample_ok se establece en " verdadero " o " falso " después de que se hayan ejecutado todas las afirmaciones.
Extractor de expresiones regulares ¶
Permite al usuario extraer valores de una respuesta del servidor utilizando una expresión regular de tipo Perl. Como posprocesador, este elemento se ejecutará después de cada solicitud de muestra en su ámbito, aplicando la expresión regular, extrayendo los valores solicitados, generando la cadena de plantilla y almacenando el resultado en el nombre de variable dado.

Parámetros ¶
- Solo muestra principal : solo se aplica a la muestra principal
- Solo submuestras: solo se aplica a las submuestras
- Muestra principal y submuestras : se aplica a ambas.
- Nombre de la variable JMeter a usar : la extracción se debe aplicar al contenido de la variable nombrada
- Cuerpo : el cuerpo de la respuesta, por ejemplo, el contenido de una página web (excluyendo los encabezados)
-
Cuerpo (sin escape) : el cuerpo de la respuesta, con todos los códigos de escape Html reemplazados. Tenga en cuenta que los escapes HTML se procesan sin tener en cuenta el contexto, por lo que se pueden realizar algunas sustituciones incorrectas.
Tenga en cuenta que esta opción tiene un gran impacto en el rendimiento, así que utilícela solo cuando sea absolutamente necesario y sea consciente de sus impactos.
-
Cuerpo como documento : el texto extraído de varios tipos de documentos a través de Apache Tika (consulte la sección Ver el documento del árbol de resultados ).
Tenga en cuenta que la opción Cuerpo como documento puede afectar el rendimiento, así que asegúrese de que esté bien para su prueba.
- Encabezados de solicitud : es posible que no estén presentes para muestras que no sean HTTP
- Encabezados de respuesta : es posible que no estén presentes para muestras que no sean HTTP
- URL
- Código de respuesta - por ejemplo, 200
- Mensaje de respuesta - por ejemplo, OK
- Use un valor de cero para indicar que JMeter debe elegir una coincidencia al azar.
- Un número positivo N significa seleccionar la n -ésima coincidencia.
- Los números negativos se utilizan junto con el controlador ForEach ; consulte a continuación.
Sin embargo, si tiene varios elementos de prueba que configuran la misma variable, es posible que desee dejar la variable sin cambios si la expresión no coincide. En este caso, elimine el valor predeterminado una vez que se complete la depuración.
Si el número de coincidencia se establece en un número no negativo y se produce una coincidencia, las variables se establecen de la siguiente manera:
- refName - el valor de la plantilla
- refName_g n , donde n = 0 , 1 , 2 - los grupos para el partido
- refName_g - el número de grupos en Regex (excluyendo 0 )
Si no se produce ninguna coincidencia, la variable refName se establece en el valor predeterminado (a menos que esté ausente). Además, se eliminan las siguientes variables:
- refNombre_g0
- refNombre_g1
- refNombre_g
Si el número de coincidencia se establece en un número negativo, se procesan todas las coincidencias posibles en los datos del muestreador. Las variables se establecen de la siguiente manera:
- refName_matchNr - el número de coincidencias encontradas; podría ser 0
- refName_ n , donde n = 1 , 2 , 3 etc . - las cadenas generadas por la plantilla
- refName_ n _g m , donde m = 0 , 1 , 2 - los grupos para la coincidencia n
- refName : siempre establecido en el valor predeterminado
- refName_g n - no establecido
Tenga en cuenta que la variable refName siempre se establece en el valor predeterminado en este caso, y las variables de grupo asociadas no se establecen.
Consulte también Aserción de respuesta para ver algunos ejemplos de cómo especificar modificadores y para obtener más información sobre las expresiones regulares de JMeter.
Extractor de selector de CSS (antes: Extractor de CSS/JQuery) ¶
Permite al usuario extraer valores de una respuesta HTML del servidor mediante una sintaxis de selector de CSS. Como posprocesador, este elemento se ejecutará después de cada solicitud de muestra en su ámbito, aplicando la expresión CSS/JQuery, extrayendo los nodos solicitados, extrayendo el nodo como texto o valor de atributo y almacenando el resultado en el nombre de variable dado.

Parámetros ¶
- Solo muestra principal : solo se aplica a la muestra principal
- Solo submuestras: solo se aplica a las submuestras
- Muestra principal y submuestras : se aplica a ambas.
- Nombre de la variable JMeter a usar : la extracción se debe aplicar al contenido de la variable nombrada
- E[foo] - un elemento E con un atributo " foo "
- ancestro secundario : elementos secundarios que descienden del ancestro, por ejemplo, .body p encuentra p elementos en cualquier lugar debajo de un bloque con clase " cuerpo "
- :lt(n) - encuentra elementos cuyo índice de hermanos (es decir, su posición en el árbol DOM en relación con su padre) es menor que n ; por ejemplo , td:lt(3)
- :contains(text) - encuentra elementos que contienen el texto dado . La búsqueda no distingue entre mayúsculas y minúsculas; p : contiene (jsopa)
- …
Esta es la función Element#attr(name) equivalente para JSoup si se establece un atributo.
Si está vacío, es el equivalente de la función Element#text() para JSoup si no se establece un valor para el atributo.

- Use un valor de cero para indicar que JMeter debe elegir una coincidencia al azar.
- Un número positivo N significa seleccionar la n -ésima coincidencia.
- Los números negativos se utilizan junto con el controlador ForEach ; consulte a continuación.
Sin embargo, si tiene varios elementos de prueba que configuran la misma variable, es posible que desee dejar la variable sin cambios si la expresión no coincide. En este caso, elimine el valor predeterminado una vez que se complete la depuración.
Si el número de coincidencia se establece en un número no negativo y se produce una coincidencia, las variables se establecen de la siguiente manera:
- refName - el valor de la plantilla
Si no se produce ninguna coincidencia, la variable refName se establece en el valor predeterminado (a menos que esté ausente).
Si el número de coincidencia se establece en un número negativo, se procesan todas las coincidencias posibles en los datos del muestreador. Las variables se establecen de la siguiente manera:
- refName_matchNr - el número de coincidencias encontradas; podría ser 0
- refName_n , donde n = 1 , 2 , 3 , etc. - las cadenas generadas por la plantilla
- refName : siempre establecido en el valor predeterminado
Tenga en cuenta que la variable refName siempre se establece en el valor predeterminado en este caso.
Extractor XPath2 ¶

Parámetros ¶
- Solo muestra principal : solo se aplica a la muestra principal
- Solo submuestras: solo se aplica a las submuestras
- Muestra principal y submuestras : se aplica a ambas.
- Nombre de la variable JMeter a usar : la extracción se debe aplicar al contenido de la variable nombrada
Por ejemplo , //título devolvería " <título>Apache JMeter</título> " en lugar de " Apache JMeter ".
En este caso, //título/texto() devolvería " Apache JMeter ".
- 0 : significa aleatorio (valor predeterminado)
- -1 significa extraer todos los resultados, se nombrarán como <nombre de variable> _N (donde N va de 1 a Número de resultados)
- X : significa extraer el resultado X. Si este X es mayor que el número de coincidencias, no se devuelve nada. Se utilizará el valor predeterminado
Para permitir su uso en un controlador ForEach , funciona exactamente igual que el extractor XPath anterior
XPath2 Extractor proporciona algunas herramientas interesantes, como una sintaxis mejorada y muchas más funciones que en su primera versión.
Aquí hay algunos ejemplos:
- abs(/libro/pagina[2])
- extrae el segundo valor absoluto de la página de un libro
- avg(/biblioteca/libro/pagina)
- extrae el número medio de páginas de todos los libros de las bibliotecas
- comparar(/libro[1]/página[2],/libro[2]/página[2])
- devuelve un valor entero igual a 0 si la 2ª página del primer libro es igual a la 2ª página del 2º libro, de lo contrario, devuelve -1.
Para ver más información sobre estas funciones, consulte Funciones xPath2
Extractor XPath ¶

Parámetros ¶
- Solo muestra principal : solo se aplica a la muestra principal
- Solo submuestras: solo se aplica a las submuestras
- Muestra principal y submuestras : se aplica a ambas.
- Nombre de la variable JMeter a usar : la extracción se debe aplicar al contenido de la variable nombrada
- " Use Tidy " debe estar marcado para la respuesta HTML. Dicha respuesta se convierte a XHTML válido (HTML compatible con XML) usando Tidy
- " Use Tidy " debe estar desmarcado para la respuesta XHTML o XML (por ejemplo, RSS)
Por ejemplo , //título devolvería " <título>Apache JMeter</título> " en lugar de " Apache JMeter ".
En este caso, //título/texto() devolvería " Apache JMeter ".
- 0 : significa aleatorio
- -1 significa extraer todos los resultados (valor predeterminado), se nombrarán como <nombre de variable> _N (donde N va de 1 a Número de resultados)
- X : significa extraer el resultado X. Si este X es mayor que el número de coincidencias, no se devuelve nada. Se utilizará el valor predeterminado
Para permitir el uso en un controlador ForEach , las siguientes variables se establecen en el retorno:
- refName : se establece en la primera (o única) coincidencia; si no hay coincidencia, se establece en predeterminado
- refName_matchNr - establecer el número de coincidencias (puede ser 0 )
- refName_n - n = 1 , 2 , 3 , etc. Establecer en la 1 ª , 2 ª 3 ª coincidencia etc.
XPath es un lenguaje de consulta destinado principalmente a las transformaciones XSLT. Sin embargo, también es útil como lenguaje de consulta genérico para datos estructurados. Consulte la referencia de XPath o la especificación de XPath para obtener más información. Aquí hay algunos ejemplos:
- /html/cabeza/título
- extrae el elemento del título de la respuesta HTML
- /libro/pagina[2]
- extrae la segunda página de un libro
- /página de libro
- extrae todas las páginas de un libro
- //formulario[@name='countryForm']//select[@name='country']/option[text()='Czech Republic'])/@value
- extrae el atributo de valor del elemento de opción que coincide con el texto ' República Checa ' dentro del elemento seleccionado con el atributo de nombre ' país ' dentro del formulario con el atributo de nombre ' countryForm '
- Todos los elementos y nombres de atributos se convierten a minúsculas
- Tidy intenta corregir elementos incorrectamente anidados. Por ejemplo: original (incorrecto) ul/font/li se convierte en correcto ul/li/font
Como una ronda de trabajo para las limitaciones de espacio de nombres del analizador Xalan XPath (implementación en la que se basa JMeter), debe:
- proporcione un archivo de propiedades (si, por ejemplo, su archivo se llama namespaces.properties ) que contiene asignaciones para los prefijos de espacio de nombres:
prefijo1=http\://foo.apache.org prefijo2=http\://toto.apache.org …
- haga referencia a este archivo en el archivo user.properties usando la propiedad:
xpath.namespace.config=espacios de nombres.propiedades
//miespaciodenombres:etiqueta
//*[local-name()='tagname' y namespace-uri()='uri-for-namespace']uri-para-namespace mynamespace
Extractor JSON JMESPath ¶

Parámetros ¶
- Solo muestra principal : solo se aplica a la muestra principal
- Solo submuestras: solo se aplica a las submuestras
- Muestra principal y submuestras : se aplica a ambas.
- Nombre de la variable JMeter a usar : la extracción se debe aplicar al contenido de la variable nombrada
- 0 : significa aleatorio
- -1 significa extraer todos los resultados (valor predeterminado), se nombrarán como <nombre de variable> _N (donde N va de 1 a Número de resultados)
- X : significa extraer el resultado X. Si este X es mayor que el número de coincidencias, no se devuelve nada. Se utilizará el valor predeterminado
JMESPath es un lenguaje de consulta para JSON. Se describe en una gramática ABNF con una especificación completa. Esto asegura que la sintaxis del lenguaje esté definida con precisión. Consulte la referencia de JMESPath para obtener más información. Aquí también hay algunos ejemplos JMESPath Example .
Controlador de acción de estado de resultado ¶

Parámetros ¶
- Continuar : ignorar el error y continuar con la prueba
- Iniciar el ciclo del siguiente subproceso : no ejecuta muestras que siguen a la muestra por error para la iteración actual y reinicia el ciclo en la siguiente iteración
- Detener subproceso : finaliza el subproceso actual
- Detener prueba : toda la prueba se detiene al final de cualquier muestra actual.
- Detener prueba ahora : toda la prueba se detiene abruptamente. Cualquier muestra actual se interrumpe si es posible.
Postprocesador BeanShell ¶
El preprocesador BeanShell permite aplicar código arbitrario después de tomar una muestra.
BeanShell Post-Processor ya no ignora las muestras con datos de resultados de longitud cero
Para obtener detalles completos sobre el uso de BeanShell, consulte el sitio web de BeanShell.
El elemento de prueba admite los métodos ThreadListener y TestListener . Estos deben definirse en el archivo de inicialización. Consulte el archivo BeanShellListeners.bshrc para ver definiciones de ejemplo.

Parámetros ¶
- Parámetros : cadena que contiene los parámetros como una sola variable
- bsh.args : matriz de cadenas que contiene parámetros, dividida en espacios en blanco
Las siguientes variables de BeanShell están configuradas para que las use el script:
- log - ( Registrador ) - se puede usar para escribir en el archivo de registro
- ctx - ( JMeterContext ) - da acceso al contexto
-
vars - (JMeterVariables ) - otorga acceso de lectura/escritura a las variables:
vars.get(clave); vars.put(clave,valor); vars.putObject("OBJ1",nuevo Objeto()); - props - (JMeterProperties - clase java.util.Properties) - por ejemplo, props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - da acceso al SampleResult anterior
- datos - (byte [])- da acceso a los datos de muestra actuales
Para obtener detalles de todos los métodos disponibles en cada una de las variables anteriores, consulte el Javadoc
Si se define la propiedad beanshell.postprocessor.init , se usa para cargar un archivo de inicialización, que se puede usar para definir métodos, etc. para usar en el script BeanShell.
Postprocesador JSR223 ¶
El posprocesador JSR223 permite aplicar el código de script JSR223 después de tomar una muestra.
Parámetros ¶
- Parámetros : cadena que contiene los parámetros como una sola variable
- args : matriz de cadenas que contiene parámetros, dividida en espacios en blanco
Antes de invocar el script, se configuran algunas variables. Tenga en cuenta que estas son variables JSR223, es decir, se pueden usar directamente en el script.
- log - ( Registrador ) - se puede usar para escribir en el archivo de registro
- Etiqueta : la etiqueta de cadena
- FileName : el nombre del archivo de script (si lo hay)
- Parámetros : los parámetros (como una cadena)
- args : los parámetros como una matriz de cadenas (divididos en espacios en blanco)
- ctx - ( JMeterContext ) - da acceso al contexto
-
vars - ( JMeterVariables ) - otorga acceso de lectura/escritura a las variables:
vars.get(clave); vars.put(clave,valor); vars.putObject("OBJ1",nuevo Objeto()); vars.getObject("OBJ2"); - props - (JMeterProperties - clase java.util.Properties) - por ejemplo, props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - da acceso al SampleResult anterior (si lo hay)
- sampler - ( Sampler )- da acceso a la muestra actual
- OUT - System.out - por ejemplo, OUT.println("mensaje")
Para obtener detalles de todos los métodos disponibles en cada una de las variables anteriores, consulte el Javadoc
Postprocesador JDBC ¶
El posprocesador de JDBC le permite ejecutar alguna instrucción SQL justo después de que se haya ejecutado una muestra. Esto puede ser útil si su muestra de JDBC cambia algunos datos y desea restablecer el estado anterior a la ejecución de la muestra de JDBC.
En el plan de prueba vinculado, " Postprocesador de JDBC " El postprocesador de JDBC llama a un procedimiento almacenado para eliminar de la base de datos el límite de precio creado por el preprocesador.

Extractor de JSON ¶
El posprocesador JSON le permite extraer datos de las respuestas JSON mediante la sintaxis JSON-PATH. Este posprocesador es muy similar al extractor de expresiones regulares. Debe colocarse como elemento secundario de HTTP Sampler o cualquier otra muestra que tenga respuestas. Le permitirá extraer de una manera muy fácil contenido de texto, consulte la sintaxis de JSON Path .
Parámetros ¶
- 0 : significa aleatorio (valor predeterminado)
- -1 significa extraer todos los resultados, se nombrarán como <nombre de variable> _N (donde N va de 1 a Número de resultados)
- X : significa extraer el resultado X. Si este X es mayor que el número de coincidencias, no se devuelve nada. Se utilizará el valor predeterminado

Extractor de límites ¶
Permite al usuario extraer valores de una respuesta del servidor utilizando límites izquierdo y derecho. Como posprocesador, este elemento se ejecutará después de cada solicitud de muestra en su ámbito, probando los límites, extrayendo los valores solicitados, generando la cadena de plantilla y almacenando el resultado en el nombre de variable dado.

Parámetros ¶
- Solo muestra principal : solo se aplica a la muestra principal
- Solo submuestras: solo se aplica a las submuestras
- Muestra principal y submuestras : se aplica a ambas.
- Nombre de la variable JMeter a usar : la aserción se debe aplicar al contenido de la variable nombrada
- Cuerpo : el cuerpo de la respuesta, por ejemplo, el contenido de una página web (excluyendo los encabezados)
-
Cuerpo (sin escape) : el cuerpo de la respuesta, con todos los códigos de escape Html reemplazados. Tenga en cuenta que los escapes HTML se procesan sin tener en cuenta el contexto, por lo que se pueden realizar algunas sustituciones incorrectas.
Tenga en cuenta que esta opción tiene un gran impacto en el rendimiento, así que utilícela solo cuando sea absolutamente necesario y sea consciente de sus impactos.
-
Cuerpo como documento : el texto extraído de varios tipos de documentos a través de Apache Tika (consulte la sección Ver el documento del árbol de resultados ).
Tenga en cuenta que la opción Cuerpo como documento puede afectar el rendimiento, así que asegúrese de que esté bien para su prueba.
- Encabezados de solicitud : es posible que no estén presentes para muestras que no sean HTTP
- Encabezados de respuesta : es posible que no estén presentes para muestras que no sean HTTP
- URL
- Código de respuesta - por ejemplo, 200
- Mensaje de respuesta - por ejemplo, OK
- Use un valor de cero para indicar que JMeter debe elegir una coincidencia al azar.
- Un número positivo N significa seleccionar la n -ésima coincidencia.
- Los números negativos se utilizan junto con el controlador ForEach ; consulte a continuación.
Sin embargo, si tiene varios elementos de prueba que configuran la misma variable, es posible que desee dejar la variable sin cambios si la expresión no coincide. En este caso, elimine el valor predeterminado una vez que se complete la depuración.
Si el número de coincidencia se establece en un número no negativo y se produce una coincidencia, las variables se establecen de la siguiente manera:
- refName - el valor de la extracción
Si no se produce ninguna coincidencia, la variable refName se establece en el valor predeterminado (a menos que esté ausente).
Si el número de coincidencia se establece en un número negativo, se procesan todas las coincidencias posibles en los datos del muestreador. Las variables se establecen de la siguiente manera:
- refName_matchNr - el número de coincidencias encontradas; podría ser 0
- refName_ n , donde n = 1 , 2 , 3 etc . - las cadenas generadas por la plantilla
- refName_ n _g m , donde m = 0 , 1 , 2 - los grupos para la coincidencia n
- refName : siempre establecido en el valor predeterminado
Tenga en cuenta que la variable refName siempre se establece en el valor predeterminado en este caso, y las variables de grupo asociadas no se establecen.
18.9 Funciones misceláneas ¶
Plan de prueba ¶
El plan de prueba es donde se especifican las configuraciones generales para una prueba.
Las variables estáticas se pueden definir para valores que se repiten a lo largo de una prueba, como nombres de servidores. Por ejemplo, la variable SERVIDOR podría definirse como www.example.com , y el resto del plan de prueba podría referirse a ella como ${SERVER} . Esto simplifica cambiar el nombre más adelante.
Si se reutiliza el mismo nombre de variable en uno o más elementos de configuración de variables definidas por el usuario , el valor se establece en la última definición del plan de prueba (leyendo de arriba a abajo). Dichas variables deben usarse para elementos que pueden cambiar entre ejecuciones de prueba, pero que permanecen iguales durante una ejecución de prueba.
Al seleccionar Prueba funcional, se indica a JMeter que guarde la información adicional de la muestra (datos de respuesta y datos de muestra) en todos los archivos de resultados. Esto aumenta los recursos necesarios para ejecutar una prueba y puede afectar negativamente el rendimiento de JMeter. Si se requieren más datos solo para una muestra en particular, agréguele un Listener y configure los campos según sea necesario.
Además, aquí existe una opción para indicar a JMeter que ejecute Thread Group en serie en lugar de en paralelo.
Ejecutar grupos de subprocesos de desmontaje después del cierre de los subprocesos principales: si se selecciona, los grupos de desmontaje (si los hay) se ejecutarán después del cierre correcto de los subprocesos principales. Los subprocesos de desmontaje no se ejecutarán si la prueba se detiene a la fuerza.
El plan de prueba ahora proporciona una manera fácil de agregar la configuración de classpath a un plan de prueba específico. La característica es aditiva, lo que significa que puede agregar archivos o directorios jar, pero eliminar una entrada requiere reiniciar JMeter.
Las propiedades de JMeter también proporcionan una entrada para cargar classpaths adicionales. En jmeter.properties , edite " user.classpath " o " plugin_dependency_paths " para incluir bibliotecas adicionales. Consulte Classpath de JMeter y Configuración de JMeter para obtener más información.

Grupo de hilos ¶
Un grupo de subprocesos define un grupo de usuarios que ejecutarán un caso de prueba particular contra su servidor. En la GUI del grupo de subprocesos, puede controlar la cantidad de usuarios simulados (cantidad de subprocesos), el tiempo de aceleración (cuánto tiempo lleva iniciar todos los subprocesos), la cantidad de veces para realizar la prueba y, opcionalmente, un inicio y detener el tiempo para la prueba.
Véase también tearDown Thread Group y setUp Thread Group .
Cuando se utiliza el planificador, JMeter ejecuta el grupo de subprocesos hasta que se alcanza el número de bucles o se alcanza la duración/hora de finalización, lo que ocurra primero. Tenga en cuenta que la condición solo se verifica entre muestras; cuando se alcanza la condición final, ese hilo se detendrá. JMeter no interrumpe los muestreadores que están esperando una respuesta, por lo que la hora de finalización puede retrasarse arbitrariamente.

Desde JMeter 3.0, puede ejecutar una selección de Thread Group seleccionándolos y haciendo clic derecho. Aparecerá un menú emergente:

Observe que tiene tres opciones para ejecutar la selección de grupos de subprocesos:
- comienzo
- Iniciar solo los grupos de subprocesos seleccionados
- Empezar sin pausas
- Inicie solo los grupos de subprocesos seleccionados pero sin ejecutar los temporizadores
- Validar
- Inicie los grupos de hilos seleccionados solo usando el modo de validación. Por defecto, esto ejecuta el grupo de subprocesos en modo de validación (ver más abajo)
este modo permite la validación rápida de un grupo de subprocesos al ejecutarlo con un subproceso, una iteración, sin temporizadores y sin retardo de inicio establecido en 0 . El comportamiento se puede modificar con algunas propiedades configurando en user.properties :
- testplan_validation.nb_threads_per_thread_group
- Número de subprocesos a usar para validar un grupo de subprocesos, por defecto 1
- testplan_validation.ignore_timers
- Ignorar los temporizadores al validar el grupo de subprocesos del plan, por defecto 1
- testplan_validation.number_iterations
- Número de iteraciones a utilizar para validar un grupo de subprocesos
- testplan_validation.tpc_force_100_pct
- Si forzar a Throughput Controller en modo de porcentaje para que se ejecute como si el porcentaje fuera 100 %. Predeterminado a falso
Parámetros ¶
- Continuar : ignorar el error y continuar con la prueba
- Iniciar el siguiente ciclo de subprocesos : ignore el error, inicie el siguiente ciclo y continúe con la prueba
- Detener subproceso : finaliza el subproceso actual
- Detener prueba : toda la prueba se detiene al final de cualquier muestra actual.
- Detener prueba ahora : toda la prueba se detiene abruptamente. Cualquier muestra actual se interrumpe si es posible.
Si no se selecciona, todos los subprocesos se crean cuando comienza la prueba (luego hacen una pausa durante la proporción adecuada del tiempo de aceleración). Este es el valor predeterminado original y es adecuado para las pruebas en las que los subprocesos están activos durante la mayor parte de la prueba.
Administrador SSL ¶
SSL Manager es una forma de seleccionar un certificado de cliente para que pueda probar aplicaciones que usan Infraestructura de clave pública (PKI). Solo es necesario si no ha configurado las propiedades del sistema adecuadas.
Puede utilizar un almacén de claves con formato Java Key Store (JKS) o un archivo de estándar de certificado de clave pública n.º 12 (PKCS12) para sus certificados de cliente. Hay una función de las bibliotecas JSSE que requiere que tenga al menos una contraseña de seis caracteres en su clave (al menos para la utilidad keytool que viene con su JDK).
Para seleccionar el certificado de cliente, seleccione en la barra de menú. Se le presentará un buscador de archivos que busca archivos PKCS12 de forma predeterminada. Su archivo PKCS12 debe tener la extensión ' .p12 ' para que SSL Manager lo reconozca como un archivo PKCS12. Cualquier otro archivo se tratará como un almacén de claves JKS promedio. Si JSSE está instalado correctamente, se le solicitará la contraseña. El cuadro de texto no oculta los caracteres que escribes en este punto, así que asegúrate de que nadie esté mirando por encima de tu hombro. La implementación actual asume que la contraseña para el almacén de claves es también la contraseña para la clave privada del cliente con el que desea autenticarse.
O puede establecer las propiedades del sistema apropiadas; consulte el archivo system.properties .
La próxima vez que ejecute su prueba, SSL Manager examinará su almacén de claves para ver si tiene al menos una clave disponible. Si solo hay una clave, SSL Manager la seleccionará por usted. Si hay más de una clave, actualmente selecciona la primera clave. Actualmente no hay forma de seleccionar otras entradas en el almacén de claves, por lo que la clave deseada debe ser la primera.
Cosas a tener en cuentaDebe tener su certificado de autoridad de certificación (CA) instalado correctamente si no está firmado por uno de los cinco certificados de CA que se envían con su JDK. Un método para instalarlo es importar su certificado CA a un archivo JKS y nombrar el archivo JKS " jssecacerts ". Coloque el archivo en la carpeta lib/security de su JRE . Este archivo se leerá antes que el archivo " cacerts " en el mismo directorio. Tenga en cuenta que mientras exista el archivo " jssecacerts ", no se utilizarán los certificados instalados en " cacerts ". Esto puede causarle problemas. Si no le importa importar su certificado de CA en el " cacerts", entonces puede autenticarse con todos los certificados de CA instalados.
Grabador de secuencias de comandos de prueba HTTP(S) (antes: servidor proxy HTTP) ¶
El grabador de secuencias de comandos de prueba HTTP(S) permite que JMeter intercepte y registre sus acciones mientras navega por su aplicación web con su navegador normal. JMeter creará objetos de muestra de prueba y los almacenará directamente en su plan de prueba a medida que avanza (para que pueda ver las muestras de forma interactiva mientras las crea).
Asegúrese de leer esta página wiki para configurar correctamente JMeter.
Para usar la grabadora, agregue el elemento Grabadora de secuencias de comandos de prueba HTTP(S). Haga clic con el botón derecho en el elemento Plan de prueba para obtener el menú Agregar: ( ).
La grabadora se implementa como un servidor proxy HTTP(S). Debe configurar su navegador para usar el proxy para todas las solicitudes HTTP y HTTPS.
Lo ideal es utilizar el modo de navegación privada al grabar la sesión. Esto debería garantizar que el navegador se inicie sin cookies almacenadas y evitar que se guarden ciertos cambios. Por ejemplo, Firefox no permite que las anulaciones de certificados se guarden de forma permanente.
Grabación y certificados HTTPS
Las conexiones HTTPS usan certificados para autenticar la conexión entre el navegador y el servidor web. Al conectarse a través de HTTPS, el servidor presenta el certificado al navegador. Para autenticar el certificado, el navegador verifica que el certificado del servidor esté firmado por una Autoridad de certificación (CA) que esté vinculada a una de sus CA raíz integradas.
JMeter necesita usar su propio certificado para permitirle interceptar la conexión HTTPS desde el navegador. Efectivamente, JMeter tiene que pretender ser el servidor de destino.
JMeter generará sus propios certificados. Estos se generan con un período de validez definido por la propiedad proxy.cert.validity , por defecto 7 días y contraseñas aleatorias. Si JMeter detecta que se está ejecutando bajo Java 8 o posterior, generará certificados para cada servidor de destino según sea necesario (modo dinámico) a menos que se defina la siguiente propiedad: proxy.cert.dynamic_keys=false. Al usar el modo dinámico, el certificado será para el nombre de host correcto y estará firmado por un certificado de CA generado por JMeter. De forma predeterminada, el navegador no confiará en este certificado de CA; sin embargo, se puede instalar como un certificado de confianza. Una vez hecho esto, los certificados de servidor generados serán aceptados por el navegador. Esto tiene la ventaja de que incluso los recursos HTTPS incrustados pueden interceptarse y no es necesario anular las comprobaciones del navegador para cada nuevo servidor.
A menos que se proporcione un almacén de claves (y defina la propiedad proxy.cert.alias ), JMeter necesita usar la aplicación keytool para crear las entradas del almacén de claves. JMeter incluye código para verificar que keytool esté disponible buscando en varios lugares estándar. Si JMeter no puede encontrar la aplicación keytool, informará un error. Si es necesario, la propiedad del sistema keytool.directory se puede usar para decirle a JMeter dónde encontrar keytool. Esto debe definirse en el archivo system.properties .
Los certificados JMeter se generan (si es necesario) cuando se presiona el botón Inicio .
Si es necesario, puede obligar a JMeter a regenerar el almacén de claves (y los certificados exportados - ApacheJMeterTemporaryRootCA[.usr|.crt] ) eliminando el archivo de almacén de claves proxyserver.jks del directorio de JMeter.
Este certificado no es uno de los certificados en los que normalmente confían los navegadores y no será para el host correcto.
Como consecuencia:
- El navegador debería mostrar un diálogo preguntándole si desea aceptar el certificado o no. Por ejemplo:
1) El nombre del servidor " www.example.com " no coincide con el nombre del certificado " _JMeter Root CA para grabación (INSTALAR SOLO SI ES TUYO) ". Alguien puede estar tratando de escucharte a escondidas. 2) El certificado para " _ JMeter Root CA para grabación (INSTALAR SOLO SI ES TUYO) " está firmado por una autoridad de certificación desconocida " _JMeter Root CA para grabación (INSTALAR SOLO SI ES TUYO) ". No es posible verificar que se trata de un certificado válido.
Deberá aceptar el certificado para permitir que JMeter Proxy intercepte el tráfico SSL para registrarlo. Sin embargo, no acepte este certificado de forma permanente; sólo debe aceptarse temporalmente. Los navegadores solo solicitan este diálogo para el certificado de la URL principal, no para los recursos cargados en la página, como imágenes, CSS o archivos JavaScript alojados en un CDN externo seguro. Si tiene tales recursos (por ejemplo, Gmail tiene), primero tendrá que navegar manualmente a estos otros dominios para aceptar el certificado de JMeter para ellos. Compruebe en jmeter.log los dominios seguros para los que necesita registrar un certificado. - Si el navegador ya ha registrado un certificado validado para este dominio, el navegador detectará JMeter como una brecha de seguridad y se negará a cargar la página. Si es así, debe eliminar el certificado de confianza del almacén de claves de su navegador.
Las versiones de JMeter a partir de la 2.10 aún admiten este método y seguirán haciéndolo si define la siguiente propiedad: proxy.cert.alias Las siguientes propiedades se pueden usar para cambiar el certificado que se usa:
- proxy.cert.directory : el directorio en el que encontrar el certificado (predeterminado = JMeter bin/ )
- proxy.cert.file : nombre del archivo de almacenamiento de claves (predeterminado " proxyserver.jks ")
- proxy.cert.keystorepass : contraseña del almacén de claves (la " contraseña " predeterminada ) [se ignora si se usa el certificado JMeter]
- proxy.cert.keypassword : contraseña de la clave del certificado (la " contraseña " predeterminada) [se ignora si se usa el certificado JMeter]
- proxy.cert.type : el tipo de certificado (predeterminado " JKS ") [Ignorado si se usa el certificado JMeter]
- proxy.cert.factory - la fábrica (por defecto " SunX509 ") [Ignorado si se usa el certificado JMeter]
- proxy.cert.alias : el alias de la clave que se utilizará. Si esto está definido, JMeter no intenta generar su(s) propio(s) certificado(s).
- proxy.ssl.protocol : el protocolo que se utilizará (predeterminado " SSLv3 ")
Instalación del certificado JMeter CA para grabación HTTPS
Como se mencionó anteriormente, cuando se ejecuta bajo Java 8, JMeter puede generar certificados para cada servidor. Para que esto funcione sin problemas, el navegador debe confiar en el certificado de firma de CA raíz utilizado por JMeter. La primera vez que se inicia la grabadora, generará los certificados si es necesario. El certificado de CA raíz se exporta a un archivo con el nombre ApacheJMeterTemporaryRootCA en el directorio de inicio actual. Cuando se hayan configurado los certificados, JMeter mostrará un cuadro de diálogo con los detalles del certificado actual. En este punto, el certificado se puede importar al navegador, según las instrucciones a continuación.
Tenga en cuenta que una vez que el certificado de CA raíz se haya instalado como una CA de confianza, el navegador confiará en cualquier certificado firmado por él. Hasta el momento en que el certificado caduque o se elimine del navegador, no advertirá al usuario que se está confiando en el certificado. Por lo tanto, cualquier persona que pueda obtener el almacén de claves y la contraseña puede usar el certificado para generar certificados que serán aceptados por cualquier navegador que confíe en el certificado CA raíz de JMeter. Por esta razón, la contraseña para el almacén de claves y las claves privadas se generan aleatoriamente y se utiliza un período de validez breve. Las contraseñas se almacenan en el área de preferencias locales. Asegúrese de que solo los usuarios de confianza tengan acceso al host con el almacén de claves.

Instalación del certificado en Firefox
Elija las siguientes opciones:
- Opciones de herramientas
- Avanzado / Certificados
- Ver certificados
- Autoridades
- Importar …
- Vaya al directorio de inicio de JMeter y haga clic en el archivo ApacheJMeterTemporaryRootCA.crt , presione Abrir
- Haga clic en Ver y verifique que los detalles del certificado coincidan con los que muestra JMeter Test Script Recorder
- Si está bien, seleccione " Confiar en esta CA para identificar sitios web " y presione Aceptar
- Cierre los cuadros de diálogo presionando Aceptar según sea necesario
Instalación del certificado en Chrome o Internet Explorer
Tanto Chrome como Internet Explorer utilizan el mismo almacén de confianza para los certificados.
- Vaya al directorio de inicio de JMeter, haga clic en el archivo ApacheJMeterTemporaryRootCA.crt y ábralo.
- Haga clic en la pestaña " Detalles " y verifique que los detalles del certificado coincidan con los que muestra JMeter Test Script Recorder
- Si está bien, vuelva a la pestaña " General ", haga clic en " Instalar certificado... " y siga las indicaciones del asistente
Instalación del certificado en Opera
- Herramientas / Preferencias / Avanzado / Seguridad
- Administrar certificados…
- Seleccione la pestaña " Intermedio ", haga clic en " Importar... "
- Vaya al directorio de inicio de JMeter, haga clic en el archivo ApacheJMeterTemporaryRootCA.usr y ábralo.

Parámetros ¶
Por ejemplo, *.ejemplo.com,*.subdominio.ejemplo.com
Tenga en cuenta que los dominios comodín solo se aplican a un nivel, es decir, abc.subdominio.ejemplo.com coincide con *.subdominio.ejemplo.com pero no con *.ejemplo.com
- No agrupe los samplers : guarde todos los samplers grabados secuencialmente, sin ningún tipo de agrupación.
- Agregue separadores entre grupos : agregue un controlador llamado " -------------- " para crear una separación visual entre los grupos. De lo contrario, las muestras se almacenan secuencialmente.
- Coloque cada grupo en un nuevo controlador : cree un nuevo controlador simple para cada grupo y almacene todas las muestras para ese grupo en él.
- Almacene solo la primera muestra de cada grupo ; solo se registrará la primera solicitud de cada grupo. Los indicadores " Seguir redireccionamientos " y " Recuperar todos los recursos integrados... " se activarán en esas muestras.
- Coloque cada grupo en un nuevo controlador de transacciones : cree un nuevo controlador de transacciones para cada grupo y almacene todas las muestras para ese grupo en él.
Grabación y redirecciones
Durante la grabación, el navegador seguirá una respuesta de redireccionamiento y generará una solicitud adicional. El Proxy registrará tanto la solicitud original como la solicitud redirigida (sujeto a las exclusiones que se configuren). Las muestras generadas tienen " Seguir redireccionamientos " seleccionado de forma predeterminada, porque generalmente es mejor.
Ahora, si JMeter está configurado para seguir la redirección durante la reproducción, emitirá la solicitud original y luego reproducirá la solicitud de redirección que se registró. Para evitar esta reproducción duplicada, JMeter intenta detectar cuándo una muestra es el resultado de una redirección anterior. Si la respuesta actual es una redirección, JMeter guardará la URL de redirección. Cuando se recibe la siguiente solicitud, se compara con la URL de redireccionamiento guardada y, si hay una coincidencia, JMeter deshabilitará la muestra generada. También agrega comentarios a la cadena de redirección. Esto supone que todas las solicitudes en una cadena de redirección se sucederán sin ninguna solicitud intermedia. Para deshabilitar la detección de redirección, establezca la propiedad proxy.redirect.disabling=false
Incluye y excluye
Los patrones de inclusión y exclusión se tratan como expresiones regulares (usando Jakarta ORO). Se compararán con el nombre de host, el puerto (real o implícito), la ruta y la consulta (si corresponde) de cada solicitud del navegador. Si la URL que está explorando es
" http://localhost/jmeter/index.html?username=xxxx ",
la expresión regular se probará con la cadena:
" localhost:80/jmeter/index.html?username=xxxx ".
Por lo tanto, si desea incluir todos los archivos .html , su expresión regular podría verse como:
" .*\.html(\?.*)? " - o " .*\.html
si sabe que no hay una cadena de consulta o solo desea páginas html sin cadenas de consulta.
Si hay patrones de inclusión, la URL debe coincidir con al menos uno de los patrones; de lo contrario, no se registrará. Si hay patrones de exclusión, la URL no debe coincidir con ninguno de los patrones, de lo contrario no se registrará. Usando una combinación de inclusiones y exclusiones, debería poder registrar lo que le interesa y omitir lo que no.
Por lo tanto, " \.html " no coincidirá con localhost:80/index.html
Captura de datos POST binarios
JMeter puede capturar datos POST binarios. Para configurar qué tipos de contenido se tratan como binarios, actualice la propiedad proxy.binary.types de JMeter . La configuración predeterminada es la siguiente:
# Estos tipos de contenido se gestionarán guardando la solicitud en un archivo: proxy.binary.types=application/x-amf,application/x-java-serialized-object # Los archivos se guardarán en este directorio: proxy.binary.directory=user.dir # Los archivos se crearán con este archivo filesuffix: proxy.binary.filesuffix=.binario
Adición de temporizadores
También es posible hacer que el proxy agregue temporizadores al guión grabado. Para hacer esto, cree un temporizador directamente dentro del componente Grabador de secuencias de comandos de prueba HTTP(S). El proxy colocará una copia de este temporizador en cada muestra que registre, o en la primera muestra de cada grupo si está utilizando la agrupación. Luego, esta copia se escaneará en busca de ocurrencias de la variable ${T} en sus propiedades, y tales ocurrencias serán reemplazadas por el intervalo de tiempo de la muestra anterior registrada (en milisegundos).
Cuando esté listo para comenzar, presione " comenzar ".
¿Dónde se registran las muestras?
JMeter coloca las muestras grabadas en el controlador de destino que elija. Si elige la opción predeterminada " Usar controlador de grabación ", se almacenarán en el primer controlador de grabación que se encuentre en el árbol de objetos de prueba (así que asegúrese de agregar un controlador de grabación antes de comenzar a grabar).
Si el Proxy no parece registrar ninguna muestra, esto podría deberse a que el navegador no está usando realmente el proxy. Para verificar si este es el caso, intente detener el proxy. Si el navegador aún descarga páginas, entonces no estaba enviando solicitudes a través del proxy. Vuelva a comprobar las opciones del navegador. Si está intentando grabar desde un servidor que se ejecuta en el mismo host, verifique que el navegador no esté configurado en " Omitir servidor proxy para direcciones locales " (este ejemplo es de IE7, pero habrá opciones similares para otros navegadores). Si JMeter no registra las URL del navegador, como http://localhost/ o http://127.0.0.1/ , intente usar el nombre de host o la dirección IP sin bucle invertido, por ejemplo, http://myhost/ o http://192.168. 0,2/ .
Manejo de valores predeterminados de solicitud HTTP
Si HTTP(S) Test Script Recorder encuentra valores predeterminados de solicitud HTTP habilitados directamente dentro del controlador donde se almacenan las muestras, o directamente dentro de cualquiera de sus controladores principales, las muestras grabadas tendrán campos vacíos para los valores predeterminados que especificó. Puede controlar aún más este comportamiento colocando un elemento de valores predeterminados de solicitud HTTP directamente dentro de la grabadora de secuencias de comandos de prueba HTTP(S), cuyos valores que no estén en blanco anularán los de los otros valores predeterminados de solicitud HTTP. Consulte Prácticas recomendadas con HTTP(S) Test Script Recorder para obtener más información.
Reemplazo de variables definidas por el usuario
De manera similar, si HTTP(S) Test Script Recorder encuentra variables definidas por el usuario (UDV) directamente dentro del controlador donde se almacenan las muestras, o directamente dentro de cualquiera de sus controladores principales, las muestras registradas tendrán cualquier ocurrencia de los valores de esas variables. reemplazada por la variable correspondiente. Una vez más, puede colocar variables definidas por el usuario directamente dentro de la grabadora de secuencias de comandos de prueba HTTP(S) para anular los valores que se reemplazarán. Consulte Prácticas recomendadas con Test Script Recorder para obtener más información.
Reemplazo por Variables: por defecto, el servidor Proxy busca todas las apariciones de valores UDV. Si define la variable WEB con el valor www , por ejemplo, la cadena www será reemplazada por ${WEB} dondequiera que se encuentre. Para evitar que esto suceda en todas partes, active la casilla de verificación " Coincidencia de expresiones regulares ". Esto le dice al servidor proxy que trate los valores como expresiones regulares (utilizando los comparadores de expresiones regulares compatibles con perl5 proporcionados por ORO).
Si se selecciona " Coincidencia de expresiones regulares ", cada variable se compilará en una expresión regular compatible con Perl encerrada entre \b( y )\b . De esa manera, cada coincidencia comenzará y terminará en un límite de palabras.
Si no desea que su expresión regular se incluya con esos emparejadores de límites, debe encerrar su expresión regular entre paréntesis, por ejemplo ('.*?') para que coincida con 'nombre' de You can call me 'name' .
Si desea hacer coincidir solo una cadena completa, enciérrela entre (^ y $) , por ejemplo (^thus$) . Los paréntesis son necesarios, ya que los caracteres de límite normalmente agregados evitarán que ^ y $ coincidan.
Si desea hacer coincidir /images solo al comienzo de una cadena, use el valor (^/images) . Jakarta ORO también admite la búsqueda anticipada de ancho cero, por lo que se puede hacer coincidir /images/... pero conservar el / final en la salida usando (^/images(?=/)) .
Esté atento a los emparejadores superpuestos. Por ejemplo, el valor .* como expresión regular en una variable llamada expresión regular coincidirá parcialmente con una variable reemplazada anteriormente, lo que dará como resultado algo como ${{regex} , que probablemente no sea el resultado deseado.
Si hay algún problema al interpretar las variables como patrones, estos se informan en jmeter.log , así que asegúrese de verificar esto si los UDV no funcionan como se esperaba.
Cuando haya terminado de grabar sus muestras de prueba, detenga el servidor proxy (presione el botón " detener "). Recuerde restablecer la configuración de proxy de su navegador. Ahora, es posible que desee ordenar y reordenar el script de prueba, agregar temporizadores, oyentes, un administrador de cookies, etc.
¿Cómo puedo grabar también las respuestas del servidor?
Simplemente coloque un agente de escucha Ver árbol de resultados como elemento secundario de la grabadora de secuencias de comandos de prueba HTTP(S) y se mostrarán las respuestas. También puede agregar un posprocesador para guardar respuestas en un archivo que guardará las respuestas en archivos.
Asociación de solicitudes con respuestas
Si define la propiedad proxy.number.requests=true , JMeter agregará un número a cada muestra y cada respuesta. Tenga en cuenta que puede haber más respuestas que muestras si se han utilizado exclusiones o inclusiones. Las respuestas que han sido excluidas tendrán etiquetas entre [ y ], por ejemplo [23 /favicon.ico]
Administrador de cookies
Si el servidor con el que está probando usa cookies, recuerde agregar un Administrador de cookies HTTP al plan de prueba cuando haya terminado de registrarlo. Durante la grabación, el navegador maneja las cookies, pero JMeter necesita un administrador de cookies para manejar las cookies durante una ejecución de prueba. El servidor JMeter Proxy transmite todas las cookies enviadas por el navegador durante la grabación, pero no las guarda en el plan de prueba porque es probable que cambien entre ejecuciones.
Administrador de autorizaciones
La grabadora de secuencias de comandos de prueba HTTP(S) toma el encabezado " Autenticación " e intenta calcular la política de autenticación. Si se agregó Authorization Manager al controlador de destino manualmente, HTTP(S) Test Script Recorder lo encontrará y agregará la autorización (se eliminarán las que coincidan). De lo contrario, el Administrador de autorización se agregará al controlador de destino con el objeto de autorización. Es posible que deba corregir los valores calculados automáticamente después de la grabación.
Subiendo archivos
Algunos navegadores (por ejemplo, Firefox y Opera) no incluyen el nombre completo de un archivo cuando cargan archivos. Esto puede hacer que el servidor proxy JMeter falle. Una solución es asegurarse de que cualquier archivo que se cargue esté en el directorio de trabajo de JMeter, ya sea copiando los archivos allí o iniciando JMeter en el directorio que contiene los archivos.
Grabación de protocolos no textuales basados en HTTP que no están disponibles de forma nativa en JMeter
Es posible que deba registrar un protocolo HTTP que JMeter no maneja de manera predeterminada (Protocolo binario personalizado, Adobe Flex, Microsoft Silverlight, …). Aunque JMeter no proporciona una implementación de proxy nativa para registrar estos protocolos, tiene la capacidad de registrar estos protocolos implementando un SamplerCreator personalizado . Este creador de muestras traducirá el formato binario a una subclase HTTPSamplerBase que se puede agregar al caso de prueba de JMeter. Para obtener más detalles, consulte "Extensión de JMeter".
Servidor espejo HTTP ¶
El servidor HTTP Mirror es un servidor HTTP muy simple: simplemente refleja los datos que se le envían. Esto es útil para comprobar el contenido de las solicitudes HTTP.
Utiliza el puerto predeterminado 8081 .

Parámetros ¶
Parámetros ¶
headerA: valueA|headerB: valueB establecería headerA en valueA y headerB en valueB .
También puede utilizar los siguientes parámetros de consulta:
Parámetros ¶
Visualización de propiedades ¶
La visualización de propiedades muestra los valores de las propiedades del sistema o JMeter. Los valores se pueden cambiar ingresando texto nuevo en la columna Valor.

Parámetros ¶
Muestra de depuración ¶
Debug Sampler genera una muestra que contiene los valores de todas las variables y/o propiedades de JMeter.
Los valores se pueden ver en el panel Ver datos de respuesta del oyente del árbol de resultados .

Parámetros ¶
Depurar postprocesador ¶
El posprocesador de depuración crea una submuestra con los detalles de las propiedades del muestreador anterior, las variables de JMeter, las propiedades y/o las propiedades del sistema.
Los valores se pueden ver en el panel Ver datos de respuesta del oyente del árbol de resultados .

Parámetros ¶
Fragmento de prueba ¶
El fragmento de prueba se utiliza junto con el controlador de inclusión y el controlador de módulo .

Parámetros ¶
configurar grupo de subprocesos ¶
Un tipo especial de ThreadGroup que se puede utilizar para realizar acciones previas a la prueba. El comportamiento de estos subprocesos es exactamente como un elemento de grupo de subprocesos normal. La diferencia es que este tipo de subprocesos se ejecutan antes de que la prueba continúe con la ejecución de los grupos de subprocesos regulares.

desmontar grupo de hilos ¶
Un tipo especial de ThreadGroup que se puede utilizar para realizar acciones posteriores a la prueba. El comportamiento de estos subprocesos es exactamente como un elemento de grupo de subprocesos normal. La diferencia es que este tipo de subprocesos se ejecutan después de que la prueba haya terminado de ejecutar sus Grupos de subprocesos habituales.

